
چتباتهای مبتنی بر هوش مصنوعی، شاید در نگاه اول منبع بیانتهایی از اطلاعات به نظر برسد که در برابر هیچ پرسشی بیپاسخ نمیمانند؛ اما کافی است چند سؤال درباره رویدادهای روز مطرح کنید تا یکی از ضعفهای اصلی این مدلها که عدم دسترسی به دادههای بهروز است، نمایان شود. برای رفع این چالش، تکنیک RAG (Retrieval-Augmented Generation) بهعنوان راهکاری نوآورانه در کنار مدلهای هوشمند قرار گرفته تا همواره به دادههای جدید، معتبر و تخصصی دسترسی داشته باشند. در این مطلب، به معرفی RAG، نحوه کارکرد، مزایا و چالشها و همچنین کاربردهای گستردهاش در صنایع مختلف میپردازیم.
RAG چیست؟
فرض کنید که یک وکیل قصد دارد از مدلهای هوش مصنوعی برای دفاع از یک پرونده استفاده کند؛ اما دراینبین، یک چالش اساسی وجود دارد؛ مدل AI موردنظر بر اساس کتابهای قانونی قدیمی آموزش دیده و به جدیدترین قوانین و تبصرهها و همچنین اطلاعات تخصصی مرتبط با پرونده دسترسی ندارد. اینجاست که RAG کاربرد خود را به نمایش میگذارد و با افزودن دیتابیسی از بهروزترین قوانین، آییننامهها، آرای قضایی و اسناد پرونده به مدل هوش مصنوعی، اطلاعاتی کاربردی و معتبر به وکیل ارائه میکند. پس به طور خلاصه میتوان گفت «RAG (Retrieval-Augmented Generation) روشی ترکیبی است که به مدلهای زبانی این امکان را میدهد تا علاوه بر دانش داخلی، از اطلاعات بهروز و تخصصی موجود در منابع بیرونی نیز بهره بگیرند و در نتیجه، پاسخهایی جامعتر و قابلاعتمادتر ارائه دهند.»
بیشتر بخوانید: مدل زبانی چیست؟
RAG چگونه کار میکند؟
برای درک بهتر اینکه RAG چگونه عمل میکند، میتوان آن را به چند مرحلهٔ کلیدی تقسیم کرد. در ادامه، این مراحل را بررسی میکنیم:
در اولین گام، دادههای مرجع به بردارهای عددی (LLM embeddings) تبدیل میشوند. دادههای مرجع میتواند شامل متون بدون ساختار، دادههای نیمهساختیافته، یا حتی دادههای ساختیافته مثل نالجگرافها باشد. پس از تبدیل دادهها به embedding، در یک پایگاه داده برداری (Vector Database) ذخیره میشوند تا امکان بازیابی سریع آنها در آینده وجود داشته باشد.
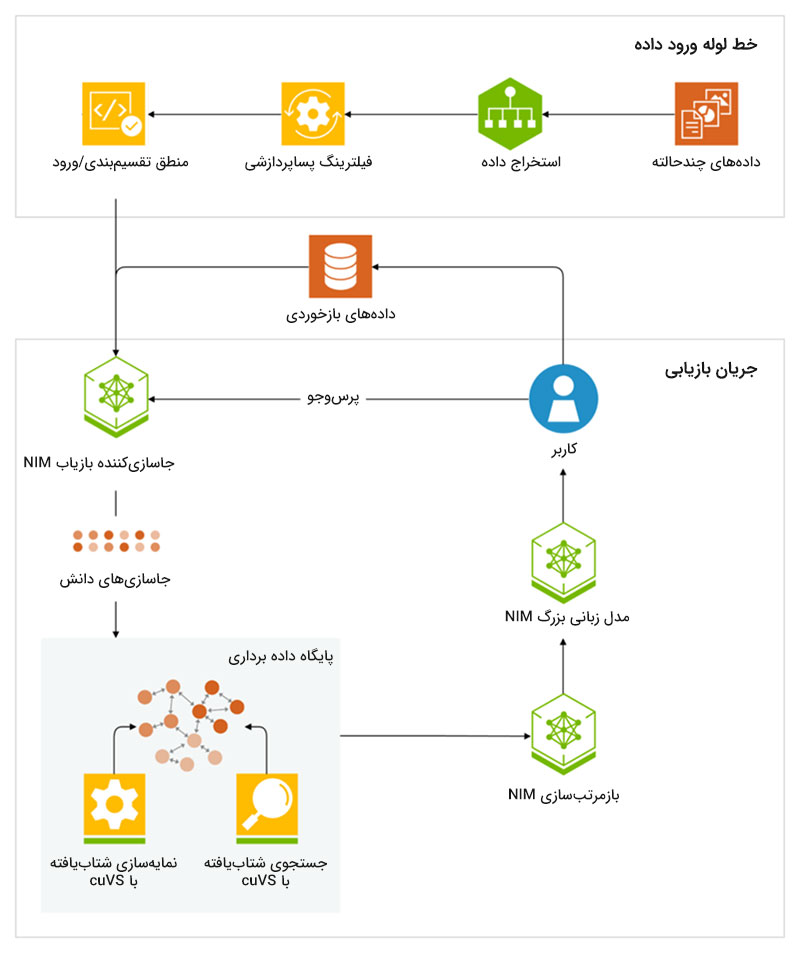
2. بازیابی (Retrieval)
زمانی که کاربر سؤال خود را از مدل زبانی میپرسد، مرحله بازیابی (Retrieval) آغاز میشود. در این مرحله، مدل سعی میکند با مراجعه به حافظه خود و همچنین دادههای ایندکس شدهای که در اختیار دارد، نزدیکترین و مرتبطترین پاسخ را در جواب پرسش کاربر ارائه کند.
3. تقویت یا غنیسازی (Augmentation)
پس از بازیابی، اسناد و اطلاعات انتخابشده به همراه پرسش اولیه کاربر به مدل زبانی منتقل میشوند. در مرحله بعدی تقویت یا غنیسازی، پرسش کاربران با دادههای بازیابیشده ترکیب میشود تا زمینهای غنیتر و دقیقتر برای پاسخگویی مدل فراهم کند.
4. تولید (Generation)
حال مدل هم سؤال کاربر را میفهمد و هم پشتوانهای از دادههای معتبر در اختیار دارد؛ بنابراین میتواند خروجیای تولید کند که دقیقتر، مرتبطتر و کاربردیتر از حالتی است که تنها از حافظه درونی خود استفاده میکند.
در مجموع، RAG با ترکیب پرسش کاربر و دادههای بازیابیشده از منابع معتبر، زمینهای تقویتشده در اختیار مدل زبانی قرار میدهد تا خروجی نهایی از دقت بیشتری برخوردار باشد.
کاربردهای RAG چیست؟
تا به اینجا به نقش روش RAG در افزایش دقت پاسخگویی مدلهای زبانی اشاره کردیم؛ اما این تنها یکی از چندین کاربرد RAG در زمینههای مختلف است. یکی دیگر از کاربردهای مؤثر این تکنیک، کاهش چشمگیر مشکل خطا یا Hallucination مدلها از طریق دسترسی به دادههای معتبر و تخصصی است. علاوهبراین، RAG میتواند تجربهای شخصیسازیشده برای سازمانها ایجاد کند و راهنمایی برای دسترسی سادهتر به اطلاعات داخلی سازمانها باشد. ترکیب قابلیت جستوجو با خلاصهسازی، دیگر قابلیت RAG است که باعث میشود کاربران بدون نیاز به مطالعه اسناد طولانی، به نتایجی منسجم و قابلفهم برسند.
بیشتر بخوانید: مدل زبانی بزرگ (LLM) چیست؟
مثالهایی از کاربرد RAG در حوزههای مختلف
دسترسی لحظهای به دادههای بهروز و تخصصی، میتواند به برگ برنده هر کسبوکاری تبدیل شود. امروزه مجموعهها این امکان را دارند که به واسطه روش RAG، مدلهای هوش مصنوعی عادی را به دستیاری متخصص و حرفهای تبدیل کنند. در ادامه، چند مثال از کاربردهای RAG در صنایع مختلف را مرور میکنیم:
- پزشکی و سلامت: دسترسی به جدیدترین پژوهشها و دستورالعملهای درمانی برای بهبود کیفیت تشخیص و معالجه.
- حقوق و مشاوره: استفاده از قوانین و آرای بهروز برای ارائه مشاورههای دقیق و قابل استناد
- مالی، بانکی و فینتک: تحلیل سریع دادههای بازار و اسناد مالی برای تصمیمگیری هوشمندانه و کاهش ریسک
- آموزش و پژوهش: فراهمسازی منابع علمی معتبر برای ارتقاء کیفیت آموزش و تحقیقات دانشگاهی
- خدمات مشتریان: پاسخگویی سریع و دقیق با اتصال به پایگاه دانش سازمانی برای افزایش رضایت مشتری
کاربردهای RAG در صنایع، تنها به موارد بالا خلاصه نمیشود و حوزههایی مانند گردشگری، خردهفروشیهای آنلاین، بیمهها، رسانهها و دهها کسبوکار دیگر هم پتانسیل آن را دارند که از طریق RAG، مزیتهای رقابتی جدیدی به دست آورند.
نگاهی به مزایا و معایب RAG
در وهله اول، اگر نگاهی اجمالی به فناوری RAG بیندازیم، مزایای آن مانند افزایش دقت مدلهای زبانی، دسترسی به اطلاعات بهروز، قابلیت شخصیسازی و… باعث میشود تصور کنیم با یک تکنیک بینقص مواجهیم؛ اما مانند هر روش دیگری، RAG هم با معایب و چالشهایی همراه است که میبایست پیش از بهکارگیری به آنها توجه کرد.
یکی از نکاتی که نباید از آن غافل شد، وابستگی شدید RAG به دادههای بیرونی است. اگر منابعی که سیستم از آنها استفاده میکند معتبر و بهروز نباشند، پاسخ نهایی هم از کیفیت قابلقبولی برخوردار نخواهد بود. از سوی دیگر، پیادهسازی این فناوری در مقایسه با مدلهای زبانی ساده پیچیدهتر است. وجود زیرساختهایی مانند پایگاه داده برداری، سیستمهای بازیابی پیشرفته و معماری یکپارچه، باعث شده تا زمان و هزینه راهاندازی RAG بهمراتب بیشتر از مدلهای زبانی معمولی باشد.
بیشتر بخوانید: مدل زبانی BERT چیست؟
چالش دیگر، نگهداری و بهروزرسانی مداوم دادهها است. دیتابیس RAG میبایست همیشه بهروز باشد و با جدیدترین دادهها تغذیه شود؛ در غیر این صورت به مرور زمان دچار افت کیفیت میشود و توانایی آن در ارائه پاسخهای دقیق و قابلاعتماد کاهش مییابد. افزودن مرحلهی بازیابی به فرایند پاسخگویی هم میتواند سرعت سیستم را تا حد زیادی کاهش دهد، بهویژه وقتی حجم دادهها بسیار زیاد است. بنابراین، نگاه واقعبینانه به مزایا و معایب RAG به ما کمک میکند تا با درک درست از نقاط قوت و محدودیتهای این فناوری، آن را در جایگاه مناسب خود به کار بگیریم.

جدیدترین تکنیکهای RAG؛ نگاهی به آیندهٔ هوش مصنوعی
روش RAG از بدو ظهور تاکنون، همواره در حال تکامل بوده و هرساله روشها و تکنیکهای تازهای معرفی میشوند تا این تکنیک دقیقتر، سریعتر و هوشمندتر شود. در این بخش با برخی از جدیدترین تکنیکهای RAG آشنا میشویم.
1. گسترش پرسش (Query Expansion)
یکی از چالشهایی که RAG همیشه با آن مواجه بوده است، انتخاب درست اسناد مرتبط با پرسش است. در تکنیکها «گسترش پرسش»، پرامپت ورودی گسترش پیدا میکند تا دامنه بیشتری از دادههای مرتبط شناسایی شود.
2. حافظه و یادگیری مداوم
نسل جدید RAG میتواند از طریق جستوجوها و بازیابیهای قبلی آموزش ببیند و در دفعات بعدی پاسخهای دقیقتر و متناسبتری ارائه دهد. این رویکرد بهنوعی RAG را از یک ابزار ایستا به یک سیستم پویا و هوشمند تبدیل میکند.
3. بازچینش و رتبهبندی پیشرفته (Re-ranking)
همه اسناد بازیابیشده از اهمیت یکسانی برخوردار نیستند و از همین رو، تکنیکهای جدید مانند Re-ranking ، اسناد را پس از بازیابی دوباره رتبهبندی میکنند تا مرتبطترین و معتبرترین دادهها در اولویت قرار بگیرند.
4. انتخاب زمینه هوشمند (Context Selection)
یکی دیگر از پیشرفتهای مهم RAG های جدید، انتخاب هوشمندانه بخشهای کلیدی از اسناد است. در Context Selection به جای آنکه کل متن به مدل داده شود، فقط بخشهای مرتبط و مهم آن انتخاب و پردازش میشوند.
بیشتر بخوانید: مدل ترنسفورمر (Transformer Model) چیست؟
آینده فناوری RAG بدون شک پر از نوآوریهای بیشتر خواهد بود و میتواند نقش مهمی در شکلگیری نسل بعدی دستیارهای هوشمند ایفا کند.
جمعبندی
اگر مدلهای زبانی را ذهنی بزرگ و خلاق بدانیم، RAG همان کتابخانه بیانتهایی است که به این ذهن کمک میکند تا به اطلاعات جدید و تخصصی دسترسی پیدا کند. ترکیب خلاقیت مدل زبانی با اطلاعات بهروز RAG، پاسخهایی را ارائه میدهد که نهتنها دقیق و قابلاتکا، بلکه منطبق با نیازهای دنیای واقعی و کاربردهایی مانند سرویس احراز هویت در سیستمهای هوشمند است. هرچند مسیر پیادهسازی RAG با چالشهایی همراه است، اما آیندهای را نوید میدهد که در آن، مدلهای هوش مصنوعی، نهتنها شنونده، بلکه مشاورانی آگاه، هوشمند و همیشه بهروز خواهند بود.








