
تصور کنید در حال گفتوگو با یک هوش مصنوعی هستید؛ او نه تنها منظور شما را درک میکند، بلکه میتواند با زبان و لحنی شبیه به خود شما پاسخ دهد، تحلیل کند و ایدههای جدید در اختیارتان بگذارد. پشت این توانایی شگفتانگیز، مفهومی نهفته است تحت عنوان «مدل زبانی». مدلی که زبان انسان را میآموزد، تقلید میکند و به شیوهای هوشمندانه با آن تعامل میکند. در این مقاله، با زبانی ساده و ملموس، سفری خواهیم داشت به دنیای این فناوری شگفتانگیز؛ از چیستی آنها گرفته تا نقش کلیدیاش در تکنولوژیهای امروزی. در ادامه مطلب همراه ما باشید.
مدل زبانی چیست؟
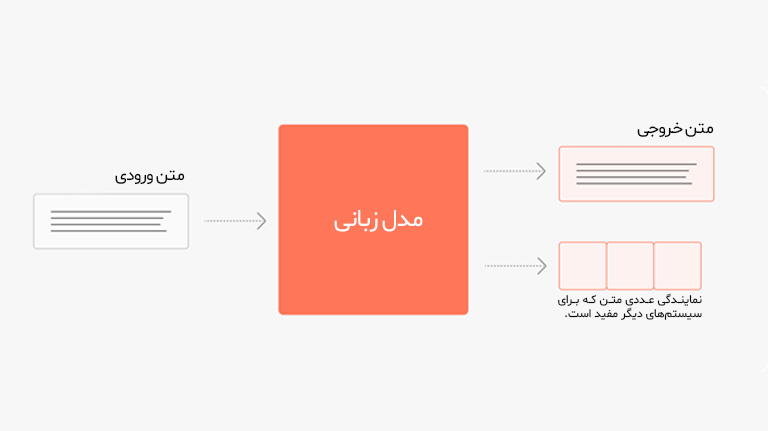
مدل زبانی (Language Model یا LM) یک سیستم مبتنی بر یادگیری ماشین است که تلاش میکند زبان انسانی را بهصورت آماری یا محاسباتی، درک و بازسازی کند. این مدلها با تحلیل حجم زیادی از متون نوشتاری، الگوهای زبانی را یاد میگیرند و میتوانند از این طریق، احتمال وقوع واژه یا جمله بعدی را با دقت بالایی تخمین بزند. برای مثال، اگر جملهای با «او امروز به» آغاز شود، مدل زبانی احتمال میدهد که کلمه بعدی ممکن است «دانشگاه»، «سرکار» یا «خانه» باشد. این تخمین براساس دانشی صورت میگیرد که مدل در طول آموزش از ساختارهای زبانی مختلف بهدست آورده است.
مدلهای زبانی معمولاً بر پایه توالیهای آماری بین واژهها کار میکنند. آنها یاد میگیرند که کدام کلمات بیشتر با یکدیگر ظاهر میشوند، کدام ساختارها طبیعیتر هستند و چگونه جمله نهایی، معنادار جلوه میکند. برخلاف آنچه بهنظر میرسد، مدل زبانی “معنا” را به شکل انسانی درک نمیکند، بلکه صرفاً تقلیدکننده ً الگوهای متنی است و سعی دارد شبیهترین متن به محتوای خلق شده توسط انسان را تولید کند.
مدلهای زبانی میتوانند بهصورت ساده (مثل مدلهای n-gram) و یا پیچیده (استفاده از شبکههای عصبی عمیق) آموزش ببینند که هرکدام کاربردهای مختص به خود را دارند. این مدلها قادرند بسته به نوع دادههای دریافت شده، لحنها و سبکهای نگارشی مختلف را تقلید کنند و به شیوههای متنوعی به دستور دریافت شده پاسخ دهند.
در مجموع، مدل زبانی، ابزاری است که بدون داشتن درک عمیق از معنای کلمات، ساختار زبان انسانی را شبیهسازی میکند و رفتهرفته با دریافت دادههای بیشتر، عملکرد خود را بهبود میبخشد. امروزه این مدلها به زبانهای گوناگونی از جمله فارسی مسلط هستند و کاربران قادرند با استفاده از زبان محلی خود با مدلهای چندزبانه تعامل برقرار کنند.
مدل زبانی چگونه کار میکند؟
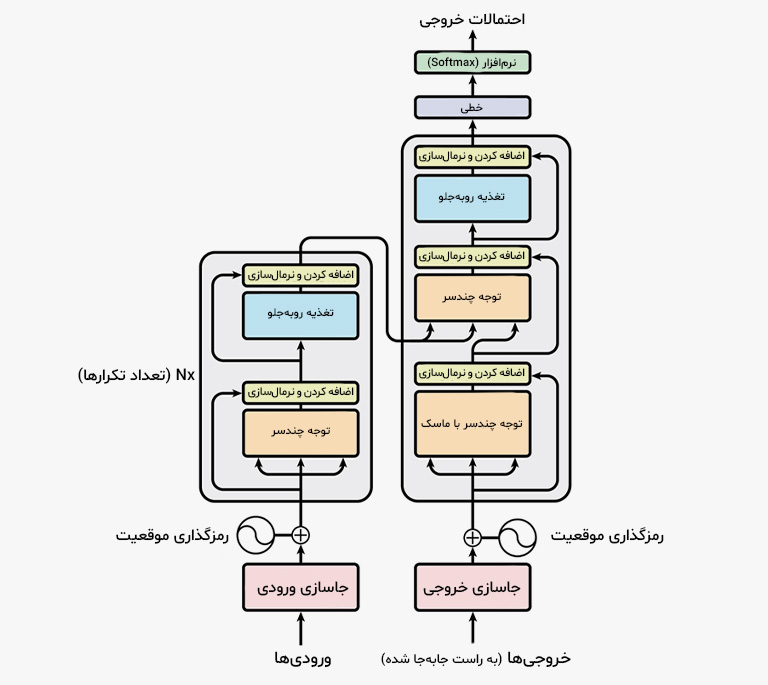
مدلهای زبانی مدرن، بهویژه مدلهای مبتنی بر مدل ترنسفورمر (Transformer)، بر پایه اصول و الگوریتمهای دقیق ریاضیاتی و مهندسی طراحی شدهاند تا مبانی زبان انسانی را یاد بگیرند و بر اساس آن، به تحلیل و تولید محتوا بپردازند. در ادامه، نگاهی دقیق به نحوهٔ عملکرد این مدلها، از سطح پایه تا جزئیات ساختاری خواهیم داشت و فرایند آموزش آنها را بررسی میکنیم.
مدل زبانی بزرگ (Large Language Model یا LLM) گونهای پیشرفتهتر از مدلهای زبانی است که با بهرهگیری از میلیاردها پارامتر و حجم عظیمی از دادههای متنی آموزش میبینند. هدف LLMها، درک، تولید و تحلیل زبان طبیعی با بالاترین میزان دقت و انعطاف ممکن است. این مدلها قادرند متون طولانی، پیچیده و چندمعنایی را پردازش کنند، مفاهیم را تعمیم دهند و در طیف وسیعی از وظایف زبانی مانند ترجمه، نگارش متن، پرسشوپاسخ یا تولید کد، عملکرد خیرهکنندهای داشته باشند. تفاوت اصلی میان «مدل زبانی» و «مدل زبانی بزرگ» در مقیاس آنها است؛ مدل زبانی میتواند ساده و کوچک باشد و برای وظایف خاصی طراحی شود، اما مدل زبانی بزرگ معمولاً چندمنظوره، قابل تعمیم و نیازمند منابع محاسباتی قابلتوجه است.
بیشتر بخوانید: مدل زبانی بزرگ (LLM) چیست؟
1. بازنمایی دادههای متنی (Tokenization)
سیستمهای کامپیوتری و بهطبع مدلهای زبانی، تنها قادر به فهم اعداد هستند و زبان نوشتاری ما پیش از اینکه تبدیل به عدد شود، هیچ معنایی برای ماشینها ندارد. در نتیجه، برای آموزش مدلهای زبانی، میبایست متون خام به قالب عددی تبدیل شوند تا مدل قادر به پردازش دادهها باشد. این فرایند توکنیزه کردن یا توکنسازی نام دارد که طی آن، هر کلمه یا عبارت به اجزاء کوچکتری تقسیم شده و هر جزء با یک توکن مشخص علامتگذاری میشود. این فرایند در سه مرحله انجام میشود:
- به هر واژه، زیر واژه یا نویسه، یک توکن اختصاص پیدا میکند.
- برای مدلهای بزرگی مانند جیپیتی، اغلب از الگوریتمهای BPE (Byte Pair Encoding) یا Unigram استفاده میشود.
در نهایت، هر توکن با یک عدد صحیح نمایش داده میشود که نمایانگر موقعیت آن در واژگان (vocabulary) مدل است.
2. جاسازی (Embedding)
پس از فرایند توکنیزه کردن، توکنهای عددی به بردارهای عددی در فضای برداری تبدیل میشوند. برای این منظور، یک ماتریس جاسازی (Embedding Matrix) وجود دارد که به هر توکن، یک بردار با فرمول زیر اختصاص میدهد:
Wx=[e1,…,eℓ]⊤
این بردارها نقش نمایش معنایی کلمات را در فضای برداری ایفا میکنند. سپس از یک تکنیک تجمیع میانگین برای فشردهسازی ماتریس استفاده میکنند:
ex=1|Wx|∑e∈Wxe
هدف این تابع، به حداکثر رساندن مقدار لگاریتم زیر است:

3. موقعیتیابی (Positional Encoding)
از آنجایی که ترنسفورمرها توالیمحور نیستند (بر خلاف RNNها)، باید ترتیب توکنها را به نحوی به مدل القا کنیم. برای دستیابی به این هدف، در مدلهای پیشرفتهای مانند GPT از روش positional embeddings استفاده میشود که به هر موقعیت متوالی، یک بردار ثابت اختصاص میدهد.
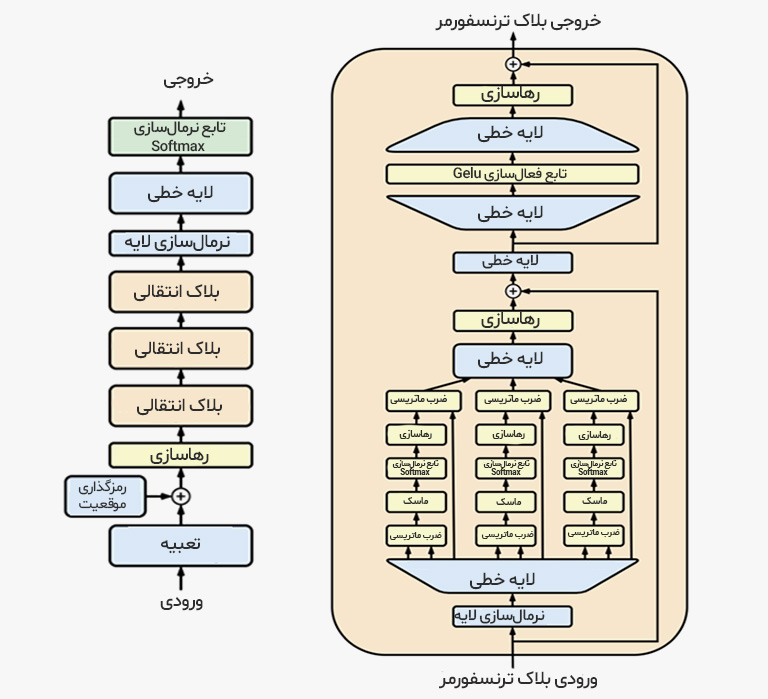
4. معماری ترنسفورمر
معماری Transformer Decoder، هسته اصلی مدلهای زبانی امروزی را شکل میدهد. این معماری از چندین لایهٔ پیاپی (stacked layers) تشکیل شده است که هر کدام شامل دو زیربخش اصلی هستند:
الف. Self-Attention با Masking
در مدلهای زبانی، از masked self-attention استفاده میشود که در آن، هر توکن فقط به توکنهای قبلی خود توجه میکند (به دلیل ماهیت پیشبینی مرحلهبهمرحله). مکانیزم attention با استفاده از سه بردار محاسبه میشود:

خروجی attention از فرمول زیر به دست میآید:

ب. لایههای Feed-Forward
پس از attention، خروجی وارد یک شبکهٔ عصبی دو لایهای با تابع فعالسازی (معمولاً GeLU) میشود:

ج. نرمالسازی و Dropout
بین مراحل، از روشهای Layer Normalization و Dropout برای پایداری یادگیری و جلوگیری از بیشبرازش استفاده میشود. در این روش، هر لایه دارای مسیرهای باقیمانده (Residual Connections) مختص به خود است که بهصورت زیر محاسبه میشود:
Sublayer (x) + LayerNorm (x) = output
5. مرحلهٔ خروجی: پیشبینی توکن بعدی
خروجی نهایی هر لایه وارد یک لایه خطی (Linear Projection) میشود که بهاندازه واژگان مدل است و پس از آن، یک تابع softmax بر روی آن اعمال میشود:

6. فرایند آموزش
در طول فرایند آموزش، مدل سعی میکند توکن بعدی را پیشبینی کند و برای دستیابی به این هدف، از تابع زیان (Cross-Entropy Loss) استفاده میکند:

پس از اعمال تابع بالا، نوبت به اعمال الگوریتم بهینهسازی است که معمولاً از الگوریتم بهینهساز AdamW استفاده میشود.
7. تولید متن (Text Generation)
مدلهای زبانی میتوانند از روشهای مختلفی برای تولید متن جدید استفاده کنند:
· Greedy Decoding: انتخاب توکن با بیشترین احتمال در هر گام
· Sampling: نمونهگیری از توزیع احتمال با دما (temperature) کنترلشده
· Top-k / Top-p Sampling: انتخاب از بین k توکن با بیشترین احتمال، یا از دامنهٔ تجمعی p
· Beam Search: نگهداشتن چند مسیر برتر به صورت همزمان برای افزایش کیفیت
8. فاز پیشآموزش و ریزتنظیم
مدل ابتدا روی یک پیکره بزرگ متنی پیشآموزش (Pretraining) میشود. سپس بسته به کاربرد، ممکن است مدل نیاز به تنظیم دقیق (Fine Tuning) داشته باشد و یا از روشهای تطبیقی بدون پارامتر مانند Prompting استفاده شود.
مدل زبانی، ترکیبی پیچیده و در عین حال زیبا از ریاضی، یادگیری ماشین و نظریه اطلاعات است. از بردارهای جاسازی گرفته تا لایههای attention و مکانیزمهای تولید متن، به مدل زبانی هوش مصنوعی کمک میکنند تا زبان انسانی را درک و آن را مدلسازی کند.
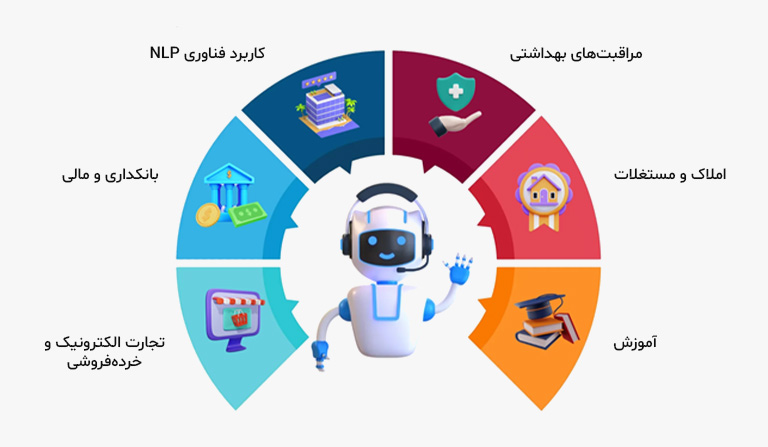
کاربردهای مدل زبانی در هوش مصنوعی
اگر بخواهیم چند مورد از کاربردیترین ابزارها در دنیای هوش مصنوعی را نام ببریم، مدل زبانی، قطعاً یکی از برترینِ آنهاست. امروزه این مدلها در صنایع مختلفی مورد استفاده قرار میگیرند و پای خود را به بسیاری از فرایندهای کسبوکارها باز کردهاند. در این بخش، به برخی از مهمترین استفادههای مدلهای زبانی خواهیم پرداخت و عمق تأثیر این فناوری بر زندگی روزمره و کسبوکارها را بررسی میکنیم.
پردازش زبان طبیعی (NLP)
اگر امروزه ماشینها قادرند زبان انسانی را با دقت بالایی درک کنند، بیشک این قابلیت را مدیون فناوری پردازش زبان طبیعی (NLP) هستند. NLP موفق شد پس از ادغام با مدلهای زبانی، به سطح تازهای از تواناییهای خود برسد و فصل تازهای را در دنیای هوش مصنوعی رقم بزند. کاربرد مدلهای زبانی در این فناوری، تنها به درک و تحلیل متون خلاصه نمیشود و از آنجا که این مدلها به زبانهای مختلفی تسلط دارند، قادرند وظیفه ترجمه متون از یک زبان به زبان دیگر را بر عهده بگیرند. پیش از این هم سیستمهای کامپیوتری میتوانستند از طریق تکنیکهای مختلف به ترجمه متون بپردازند؛ اما پس از روی کار آمدن LLMها، ترجمه ماشینی وارد مرحله جدیدی شد و در حال حاضر میتوان با استفاده از این مدلها، حجم زیادی از محتوا را از یک زبان به زبان دلخواه ترجمه کرد.
بیشتر بخوانید: پردازش گفتار چیست؟
تولید متن خودکار
تا چندی پیش، تولید محتوای متنی تنها در انحصار انسانها بود و هیچکس تصور نمیکرد روزی ماشینها بتوانند همانند ما به نگارش متن جدید بپردازند. ظهور مدلهای زبانی، این تصور را برای همیشه از بین برد و قدرت تولید متن خودکار را به سیستمهای کامپیوتری هدیه داد. هرچند که کیفیت و دقت تولید متن در نسخههای ابتدایی LLMها با مشکلات متعددی همراه بود، اما امروزه به لطف پیشرفت فناوری هوش مصنوعی، متن تولید شده توسط این مدلها تفاوت چندانی با محتوای انسانی ندارد و بهسختی میتوان تفاوت آنها را تشخیص داد. قابلیت تولید متن مدلهای زبانی، توانسته جای خود را در زمینههای مختلفی مانند بازاریابی دیجیتال، تولید مقالات، تحلیل داده و نگارش کتابها و مقالات علمی باز کند و دست کاربران را برای تولید محتوای خلاقانه باز بگذارد.
چتباتها و سیستمهای پشتیبانی از مشتری
به نظر میرسد با گسترش روزافزون مدلهای زبانی در صنایع مختلف، صفهای طولانی مشتریان برای ارتباط با اپراتورها هم در حال برچیده شدن هستند. مدلهای زبانی پیشرفته این قابلیت را دارند که به سازوکارهای یک سازمان مسلط شوند و درست مانند یک اپراتور حرفهای و مجرب، پاسخگوی مشتریان باشند. این مدلها به طور خودکار با مشتریان ارتباط برقرار میکنند، به سؤالات آنها پاسخ میدهند و با ارزیابی مسئله مطرح شده، راه حل مناسب را ارائه میکنند. این تکنولوژی بهویژه در بخشهایی مانند خدمات مشتری، سلامت، و پشتیبانی آنلاین از اهمیت بالایی برخوردار است و به کاهش هزینهها و افزایش بهرهوری کمک شایانی میکند.
تحلیل احساسات (Sentiment Analysis)
نقد، بررسی و بازخورد مشتریان در وبسایتها و شبکههای اجتماعی پیرامون یک محصول، یکی از باارزشترین دادههایی است که مجموعه میتواند به دست آورد. این دادهها شامل احساسات مختلف کاربران است که با توجه ویژه به آنها، میتوان به بسیاری از نقاط ضعف و قوت مجموعه پی برد. مسئله از جایی چالشبرانگیز میشود که تعداد این دادههای افزایش پیدا میکند و تحلیل آنها توسط نیروی انسانی دیگر امکانپذیر نیست.
بیشتر بخوانید: استفاده از سرویس تشخیص احساسات
اینجاست که مدل زبانی، پتانسیل واقعی خود را در تحلیل دادهها به نمایش میگذارد و تمامی بازخوردهای دریافت شده را طی مدت زمان کمی آنالیز میکند. از دل این تجزیهوتحلیلها، اطلاعات مفید بسیاری به دست میآید که احساسات کاربران، یکی از مهمترین آنهاست. با شناسایی روند مثبت و منفی احساسات مشتریان، تصمیمگیریهای آتی کسبوکار متحول شده و استراتژیهای مناسبی اتخاذ میشود.
جستجو و بازیابی اطلاعات
مدلهای زبانی در بهبود سیستمهای جستجو و بازیابی اطلاعات نیز نقش تأثیرگذاری دارند. با استفاده از این مدلها، موتورهای جستجو میتوانند نتایج دقیقتری را در اختیار کاربران بگذارند و گاهی با خلاصهسازی محتوا مورد نظر، لزوم جستجو در میان وبسایتهای متعدد را از بین ببرند.
تبدیل متن به گفتار
اگر مدل زبانی هوش مصنوعی بتواند متون مختلف را درک کند، پس میتواند آن را به قالبهای دیگر محتوایی هم تبدیل کند. یکی از آنها، قالب صوتی است که امکان گوشدادن به محتوای متنی را برای کاربران فراهم میکند. از کتابهای دیجیتال گرفته تا مطالب وبلاگها و مجلات خبری، میتوانند به لطف LLMها و ابزارهای هوشمندی مانند سرویس تبدیل متن به گفتار «آواشو» برای کاربران بازخوانی شوند و آنها را از چشم دوختن مداوم به صفحه نمایش بینیاز کنند.
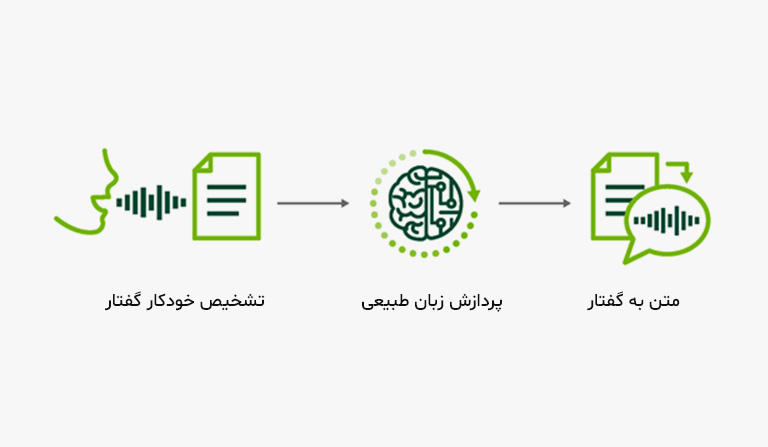
تبدیل گفتار به متن
اگر تا به حال با سیستمهای دستیار صوتی مانند Siri و Alexa تعامل داشتهاید، حتما این سؤال را از خود پرسیدهاید که این ابزارها چگونه قادرند گفتار ما را درک کنند. پاسخ این سوال در مدلهای زبانی نهفته است. LLMها با تبدیل صوت به محتوای متنی، امکان فهم مطالب بیانشده را برای سیستمهای کامپیوتری فراهم میکنند تا دیگر برای ارتباط با ماشینها، نیازی به تایپکردنهای طولانی نباشد.
امروزه ابزارهای زیادی برای تبدیل گفتار به متن در دسترس هستند که از نمونه آنها میتوان به سرویس هوشمند «آوانگار» اشاره کرد. این سرویس عملکرد خیرهکنندهای در تبدیل گفتار فارسی به متن قابل ویرایش دارد و یکی دقیقترین ابزارهای Speech To Text ایرانی بهحساب میآید.
کاربرد مدلهای زبانی تنها به موارد بالا ختم نمیشود و در زمینههای دیگری مانند تقویت موتورهای جستجو، ترجمه خودکار، شبیهسازی شخصیتهای مجازی، بهبود دسترسی برای افراد کمتوان، سیستمهای پیشنهاد دهنده و… هم بهخوبی پتانسیل خود را به نمایش میگذارند. این فناوری به مرور زمان، نقش یک مترجم، معلم، نویسنده و همکار خلاق را برعهده میگیرد و به افزایش بهرهوری و تسریع انجام کارها کمک شایانی میکند.
آشنایی با انواع مدلهای زبانی
مدلهای زبانی بسته به هدف، منابع، معماری و مقیاسشان، در دستهبندیهای متنوعی تقسیمبندی میشوند. در ادامه به چند محور مهم برای شناخت انواع مدلهای زبانی میپردازیم:
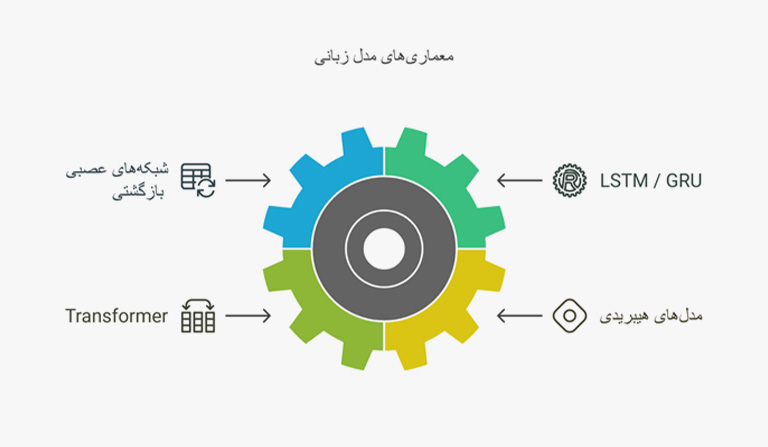
بر اساس معماری
مدلهای زبانی از معماریهای مختلفی استفاده میکنند که هر کدام مزیت و محدودیتهای خود را دارند. در ادامه، چند مورد از پرکاربردترین معماریهای LLMها را بررسی میکنیم:
شبکههای عصبی بازگشتی (RNN)
شبکههای عصبی بازگشتی (Recurrent Neural Networks)، یکی از مشهورترین معماریها در دنیای مدلهای زبانی است که برای پردازش دادههای ترتیبی مورد استفاده قرار میگیرد. این مدلها بهطور خاص برای پردازش دادههایی طراحی شدهاند که دارای ساختار توالیمحور هستند؛ دادههایی نظیر متن، صوت و سریهای زمانی که در آنها ترتیب وقوع دادهها بر معنا و تحلیل نهایی تأثیر مستقیم میگذارد.
تفاوت اصلی RNN با شبکههای عصبی پیشخور (Feedforward Neural Networks) در وجود یک حافظه داخلی است که امکان ذخیرهسازی وضعیتهای قبلی را فراهم میکند. به این ترتیب، هر ورودی جدید بهصورت مستقل پردازش میشود و درست شبیه به فرایند درک زبانی انسان، معنا را با توجه دادههای پیشین تفسیر میکند.
بیشتر بخوانید: کاربردهای شبکه عصبی
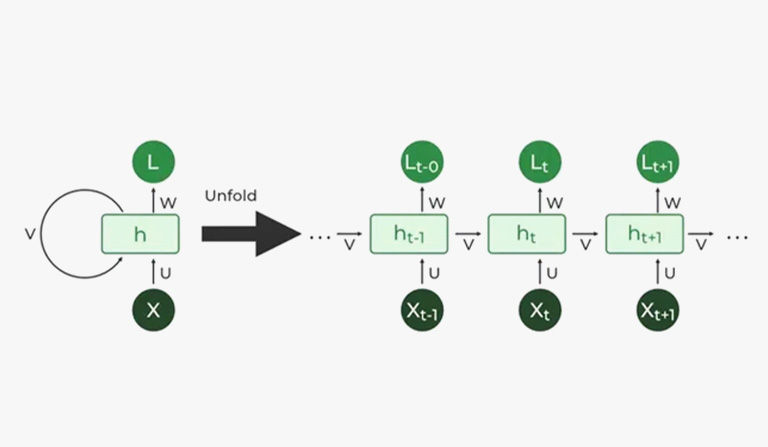
شبکههای عصبی بازگشتی (Recurrent Neural Networks)، یکی از مشهورترین معماریها در دنیای مدلهای زبانی است که برای پردازش دادههای ترتیبی مورد استفاده قرار میگیرد. این مدلها بهطور خاص برای پردازش اطلاعاتی طراحی شدهاند که دارای ساختار توالیمحور هستند؛ دادههایی نظیر متن، صوت و سریهای زمانی که در آنها ترتیب وقوع دادهها بر معنا و تحلیل نهایی تأثیر مستقیم میگذارد. تفاوت اصلی RNN با شبکههای عصبی پیشخور (Feedforward Neural Networks) در وجود یک حافظه داخلی است که امکان ذخیرهسازی وضعیتهای قبلی را فراهم میکند. به این ترتیب، هر ورودی جدید بهصورت مستقل پردازش میشود و درست شبیه به فرایند درک زبانی انسان، معنا را با توجه دادههای پیشین تفسیر میکند.
از منظر ساختاری، RNN به گونهای طراحی شده است که شبکه در قالب یک حلقه تکرارشونده عمل میکند؛ در این معماری، یک واحد محاسباتی ثابت بهصورت مکرر بر روی دادههای ورودی پیادهسازی میشود و خروجی هر مرحله به همراه ورودی مرحله جدید به شبکه بازگردانده میشود. این ویژگی به مدل اجازه میدهد تا وابستگیهای معنایی میان بخشهای مختلف یک توالی را تشخیص دهد و درک دقیقی از ساختار کلی دادهها به دست آورد.
LSTM / GRU
معماری LSTM) Long Short-Term Memory) بهعنوان نسخهای تکاملیافته از شبکههای عصبی بازگشتی و با هدف رفع یکی از چالشهای اساسی RNNهای کلاسیک یعنی محدودیت در نگهداری اطلاعات در دنبالههای طولانی توسعه پیدا کرده است. در ساختار سنتی RNN، با افزایش طول توالی دادهها، شبکه دچار افت توانایی در انتقال مؤثر اطلاعات از مراحل ابتدایی به مراحل پایانی میشود. LSTM با معرفی سازوکاری تحت عنوان سلول حافظه، موفق شد این ضعف را تا حد زیادی برطرف کند. این سلول حافظه به منزله یک مسیر اطلاعاتی پایدار عمل کرده و با بهرهگیری از مجموعهای از دروازههای کنترلی (شامل دروازه ورودی، دروازه خروجی و دروازه فراموشی)، امکان تصمیمگیری در خصوص ذخیره، حذف یا انتقال دادهها را برای مدل فراهم میکند.
در همین راستا، معماری GRU) Gated Recurrent Unit) نیز با الهام از ساختار LSTM معرفی شده است؛ با این تفاوت که طراحی آن به شکل سادهتری انجام گرفته و نیازمند منابع محاسباتی کمتری است. در GRU، برخلاف LSTM که از سه دروازه کنترلی بهره میبرد، تنها از دو دروازه کلیدی با نامهای دروازه بهروزرسانی (Update Gate) و دروازه بازنشانی (Reset Gate) برخوردار است. این ساختار سادهتر، علاوه بر تسهیل فرایند آموزش، منجر به کاهش زمان همگرایی مدل و بهبود کارایی در محیطهایی با منابع پردازشی محدود میشود. در بسیاری از مسائل عملی، GRU توانسته دقتی همتراز و حتی در برخی موارد برتر از LSTM ارائه دهد و به همین دلیل، انتخابی مقرونبهصرفه و کارآمد برای پروژههایی با محدودیت منابع به شمار میرود.
هر دو مدل LSTM و GRU نقش مؤثری در توسعه کاربردهای مختلف یادگیری ماشین از جمله در حوزههای ترجمه ماشینی، تشخیص و پردازش گفتار، پیشبینی سریهای زمانی و تولید متن ایفا کردهاند. با وجود آنکه در سالهای اخیر، معماریهای مبتنی بر Transformer بهواسطه بهرهگیری از مکانیزم توجه و قابلیت پردازش موازی، در بسیاری از پروژههای مقیاسپذیر به عنوان معماری اصلی مورد استفاده قرار میگیرند؛ اما LSTM و GRU به دلیل سادگی نسبی، بهینهبودن مصرف منابع و عملکرد قابلقبول در شرایط دادههای محدود، همچنان گزینههایی کاربردی و قابل اعتماد محسوب میشوند؛ و در برخی سناریوهای خاص، حتی برتریهای عملی نسبت به معماریهای مدرنتر ارائه میدهند.
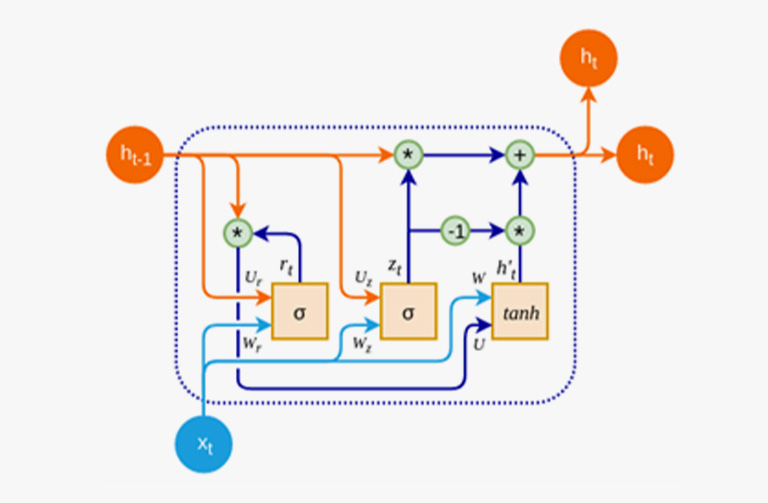
Transformer
معماری Transformer که نخستینبار توسط Ashish Vaswani و همکارانش در سال ۲۰۱۷ معرفی شد، تحولی بنیادین در حوزه پردازش زبان طبیعی و مدلهای یادگیری عمیق ایجاد کرد. این معماری با هدف رفع محدودیتهای ذاتی مدلهای بازگشتی در پردازش دنبالههای طولانی توسعه یافت و توانست در این زمینه، بهطور خیرهکنندهای موفق ظاهر شود. ویژگی اصلی Transformer، کنار گذاشتن ساختار ترتیبی سنتی و بهرهگیری از پردازش کاملاً موازی است؛ بهطوریکه میتواند تمام عناصر یک دنباله را بهطور همزمان پردازش کند. این قابلیت، سرعت آموزش را بهطور چشمگیری افزایش داده و امکان بهرهگیری از سختافزارهای محاسباتی مدرن مانند GPUها را به شکلی مؤثرتر فراهم کرده است.
بیشتر بخوانید: مدل ترنسفورمر (Transformer Model) چیست؟
هسته اصلی عملکرد Transformer بر مبنای مکانیزمی به نام Self-Attention بنا شده است. این مکانیزم به مدل اجازه میدهد تا در هر مرحله، تمامی قسمتهای دنباله را مورد توجه قرار دهد و بدون نیاز به پیمایش ترتیبی، روابط بلندمدت میان عناصر مختلف را مدلسازی کند. برخلاف شبکههای بازگشتی که وابسته به وضعیت مرحله قبلی هستند، در Transformer هر عنصر میتواند مستقیماً به سایر عناصر دسترسی داشته باشد. این امر منجر به درک دقیقتر وابستگیهای معنایی دوردست و روابط پیچیده در دادههای ورودی میشود. این رویکرد، بهویژه در پردازش متون طولانی یا دادههایی با ساختار غیرخطی، باعث شده تا معماری ترنسفورمر نسبت به معماریهای پیشین برتری قابل توجهی داشته باشد.
بر مبنای این معماری، مدلهای مدرنی چون BERT وGPT طراحی شدهاند که هر یک با بهرهگیری از قدرت پردازش موازی و یادگیری روابط طولانیمدت، مرزهای تواناییهای مدلهای زبانی را جابهجا کردهاند. مدل برت با رویکرد دوسویه و تمرکز بر درک عمیق متون، انقلابی در درک زبان طبیعی ایجاد کرد. از طرفی، معماری GPT با تأکید بر تولید متون روان و معنادار، مسیر را برای تولید زبان طبیعی و انسانگونه هموار کرد. در مجموع، معماری ترنسفورمر را میتوان ستون فقرات بسیاری از مدلهای پیشرفته امروزی دانست و انتظار میرود نقش این معماری در آینده اکوسیستم هوش مصنوعی، بیش از پیش پررنگتر شود.
معماریهای هیبریدی (Hybrid Models)
معماریهای هیبریدی (Hybrid Models) بهعنوان یکی از جدیدترین رویکردها در حوزه یادگیری ماشین و پردازش زبان طبیعی، با هدف بهرهگیری از مزایا و قابلیتهای چند معماری مختلف بهطور همزمان طراحی شدهاند. در این مدلها، عناصر کلیدی معماریهای گوناگون از جمله شبکههای بازگشتی RNN، LSTM، GRU، شبکههای کانولوشنی (CNN) و معماریهای مبتنی بر Transformer با یکدیگر ترکیب میشوند تا نقاط ضعف هر معماری به حداقل رسیده و عملکرد کلی سیستم بهبود پیدا کند. این ترکیب هوشمندانه باعث میشود مدلهای هیبریدی بتوانند هم وابستگیهای محلی و هم وابستگیهای بلندمدت در دادهها را بهخوبی شناسایی و مدلسازی کنند؛ ویژگی که هنگام استفاده از یک معماری واحد قابل دستیابی نیست.
از منظر ساختاری، مدلهای هیبریدی بسته به نوع کاربرد و داده ورودی، میتوانند به شکلهای مختلفی طراحی شوند. برای مثال، در برخی سامانههای پردازش زبان طبیعی، از CNN جهت استخراج ویژگیهای محلی (نظیر تشخیص الگوهای کوتاه در متن) و از RNN یا LSTM برای مدلسازی توالی و نگهداری وابستگیهای طولانیتر استفاده میشود. در مدلهای پیشرفتهتر، معماری Transformer نیز به این ترکیب اضافه شده تا با مکانیزم Self-Attention خود، روابط معنایی پیچیدهتر را پوشش دهد. چنین رویکردی در کاربردهایی نظیر ترجمه ماشینی، خلاصهسازی متن، تشخیص احساسات و حتی تولید زبان طبیعی، باعث بهبود دقت، افزایش قابلیت تعمیم و کاهش خطاهای ناشی از محدودیتهای ساختاری هر معماری میشود.
معماریهای هیبریدی علاوه بر ارتقای عملکرد، امکان بهینهسازی مصرف منابع را نیز فراهم میآورند و با ترکیب صحیح معماریهای سبکتر با مدلهای پیچیده، میتواند توازن مناسبی میان دقت و کارایی ایجاد کند. این رویکرد در مدلهای مدرنی همچون ERNIE و ELECTRA قابل مشاهده است که با ادغام مؤلفههای مبتنی بر Transformer و سایر سازوکارهای یادگیری ماشین، توانستهاند به نتایج قابل توجهی دست پیدا کنند. در مجموع، معماری هیبریدی با بهرهگیری از مزیتهای ترکیبی، بستری مناسب برای توسعه سیستمهای هوشمند تطبیقپذیر و کارآمد در حوزههای متنوع پردازش داده فراهم کرد است.
بر اساس اندازه و مقیاس
اندازه و مقیاس، فاکتور دیگری است که مدلهای زبانی بر اساس آن دستهبندی میشوند. به طور معمول، ال ال امها را میتوان در چهار مقیاس کلی دستهبندی کرد:
مدلهای کوچک (Small Models)
مدلهای کوچک با هدف پاسخگویی به نیازهای پردازشی سبک و محدود، طراحی شدهاند. این دسته از مدلها معمولاً تعداد پارامترهای بسیار کمتری نسبت به مدلهای متوسط و بزرگ دارند و به گونهای بهینهسازی شدهاند که بتوانند روی دستگاههای کممصرف مانند تلفنهای همراه، اینترنت اشیا (IoT)، یا سامانههای تعبیهشده (Embedded Systems) عملکرد قابل قبولی ارائه دهند. مدلهای کوچک به دلیل حجم پایینتر، نیاز کمتری به حافظه، قدرت پردازش و پهنای باند دارند و در نتیجه گزینهای ایدهآل برای کاربردهای بلادرنگ (Real-time) و محیطهای با محدودیت سختافزاری بهشمار میروند.
با وجود محدودیت در اندازه و ظرفیت، مدلهای کوچک پتانسیل آن را دارند که در بسیاری از وظایف تخصصی، عملکرد مناسبی از خود به نمایش بگذارند. خصوصاً زمانی که به طور ویژه برای انجام یک کاربرد خاص فاینتیون شوند. با این حال، این مدلها در مواجهه با دادههای پیچیدهتر یا نیاز به استنتاجهای عمیقتر دچار محدودیت میشوند. بنابراین استفاده از آنها عموماً در پروژههایی توصیه میشود که هزینه پایین و مصرف کم انرژی نسبت به دقت یا انعطافپذیری، در اولویت بالاتری قرار دارد.
مدلهای متوسط (Medium Models)
مدلهای متوسط، توازن مناسبی میان قدرت پردازش، دقت و مصرف منابع برقرار کنند. این مدلها معمولاً با تعداد پارامترهای چند صد میلیون تا چند میلیارد طراحی میشوند و قادرند طیف وسیعی از وظایف را با دقت قابل قبول و در بازههای زمانی معقول انجام دهند. مدل متوسط، گزینهای ایدهآل برای سازمانهایی است که قصد دارند با سختافزارهای میانرده و هزینه مقرونبهصرفه، خروجی مناسبی دریافت کنند.
مزیت اصلی مدلهای متوسط نسبت به مدلهای کوچک، توانایی تعمیمپذیری بالای آنهاست. مدلهای متوسط میتوانند با دادههای گوناگونی آموزش ببینند و در عین حال نسبت به مدلهای بزرگ، زمان و هزینه کمتری برای آموزش صرف میکنند. این مدلها در کاربردهایی مانند چتباتهای حرفهای، سیستمهای توصیهگر، خلاصهسازی متن و پردازش خودکار مستندات، پتانسیل خود را به نمایش میگذارند. به همین دلیل، انتخاب مدل متوسط معمولاً به معنای دستیابی به تعادلی مطلوب میان کیفیت عملکرد و محدودیتهای عملیاتی است.
مدلهای بزرگ (Large Models)
اگر قصد دارید مقیاس کار خود را گسترش دهید و از مدلهای چند میلیارد پارامتری استفاده کنید، مدلهای بزرگ میتوانند انتخاب اول شما باشند. قدرت بالای این مدلها ناشی از ظرفیت عظیم آنها در یادگیری الگوهای پیچیده، تعمیمدهی به دادههای ناشناخته و توانایی درک ظرایف دقیق زبانی است. مدلهایی مانند GPT-3، PaLM و… جزو دستهبندی مدلهای بزرگمقیاس قرار میگیرند و قادرند بدون نیاز به آموزشهای سنگین مجدد، طیف وسیعی از وظایف را انجام دهند.
با این حال، استفاده از مدلهای بزرگ با چالشهای قابل توجهی نیز همراه است. آموزش و استقرار این مدلها نیازمند منابع محاسباتی گسترده، مصرف بالای انرژی و هزینههای عملیاتی فراوان است. علاوه بر این، نگرانیهایی مانند حفظ حریم خصوصی دادهها، کنترل سوگیری (Bias) و مخاطرات امنیتی در استفاده از این مدلها، چالشی است توجه ویژهای را طلب میکند. در نتیجه، هرچند مدلهای بزرگ تواناییهای بینظیری را در اختیار کاربران خود قرار میدهند، اما استفاده از آنها نیازمند زیرساختهای تخصصی و ملاحظات جدی مدیریتی است.

مدلهای بسیار بزرگ یا مدلهای بنیادی (Foundation Models)
برای ملاقات با جدیدترین نسل مدلهای زبانی، میبایست به سراغ مدلهای بنیادی برویم. این مدلها با آموزش روی دادههای وسیع و متنوع، به عنوان زیرساختی عمومی برای طیف وسیعی از کاربردهای تخصصی مورد استفاده قرار میگیرند. مدلهای بسیار بزرگی مانند GPT-4، Grok و Gemini به گونهای طراحی شدهاند که بتوانند از طریق فاینتیونینگ (Fine-Tuning) یا پرامپتینگ (Prompting) به سرعت با نیازهای خاص تطبیق پیدا کنند. ویژگی اصلی مدلهای پایه، قابلیت تطبیقپذیری بالای آنها با حوزههای مختلف دانشی و توانایی درک و تولید متون بسیار پیچیده است.
مدلهای بنیادی به دلیل ظرفیت عظیم خود، به ابزاری کلیدی در تحول صنایع گوناگون تبدیل شدهاند. از پژوهشهای علمی و حقوقی گرفته تا تولید محتوا و توسعه نرمافزار، تنها بخش کوچکی از صنایعی هستند که طی سالهای اخیر تحت تأثیر این مدلها قرار گرفتهاند. مدلهای بنیادی با کاهش هزینههای توسعه مدلهای خاص، تسریع روند نوآوری و افزایش دسترسی به هوش مصنوعی پیشرفته، نقش مهمی در پیشرفت اکوسیستم هوش مصنوعی ایفا کردهاند. از طرفی، توسعه این مدلها نیازمند زیرساختهای فوقالعاده گرانقیمتی است که همین موضوع باعث شده تا امکان ساخت مدلهای بنیادی از دسترس بسیاری از شرکتها و حتی کشورهای درحال توسعه خارج شود.

بر اساس دادههای ورودی
مدلهای زبانی، توانایی دریافت دادههای ورودی مختلفی را دارند که بر اساس نوع دریافت این دادهها، در دستهبندیهای مشخصی قرار میگیرند.
مدلهای متنی (Text-Only Models)
نخستین و پرکاربردترین نوع مدلهای زبانی، مدلهای متنی هستند که ورودی آنها صرفاً از دادههای نوشتاری تشکیل شده است. این مدلها برای پردازش، درک و تولید متن طبیعی طراحی شدهاند و توانایی بالایی در انجام وظایفی چون ترجمه ماشینی، پاسخ به سؤالات، تولید متن خلاقانه، خلاصهسازی و طبقهبندی متون دارند. با استفاده از تکنیکهای یادگیری عمیق، این مدلها روابط آماری و معنایی میان کلمات و جملات را شناسایی کرده و میتوانند پاسخهای منسجم و معنادار ارائه دهند.
به دلیل تمرکز صرف بر متن، این مدلها نسبت به مدلهای چندحالته سادهتر هستند و منابع محاسباتی کمتری نیاز دارند. بسیاری از مدلهای زبانی کلاسیک و حتی مدلهای پیشرفتهای مانند GPT-2 یا BERT در این دسته قرار میگیرند. با اینکه قابلیت درک زمینههای غیرمتنی در این مدلها محدود است، اما همچنان در طیف وسیعی از کاربردهای زبانی تکوجهی، انتخابی بهینه و قدرتمند بهشمار میروند.
مدلهای چندوجهی (Multimodal Models)
مدلهای چندوجهی، نسل جدید مدلهای زبانی هستند که توانایی دریافت و پردازش همزمان چند نوع داده مانند متن، تصویر، صدا و ویدئو را دارند. این مدلها با ترکیب اطلاعات از منابع مختلف، به درکی جامع و عمیق نسبت به محتواهای مختلف میرسند و پیرامون فرمهای مختلف داده دریافتی، با کاربر به گفتگو مینشیند. مدلهایی مانند Llama، GPT-4 و Gemini از جمله مدلهای مشهوری هستند که در این دستهبندی جای میگیرند.
مدلهای چندحالته معمولاً با استفاده از معماریهایی چون Vision Transformer یا CLIP توسعه داده میشوند و به همترازی ویژگیها (Feature Alignment) بین رسانههای مختلف متکی هستند. هرچند توسعه و آموزش این مدلها به منابع داده متنوع و توان پردازشی قابل توجهی نیاز دارد، اما قدرت آنها در انجام وظایف پیچیده و چندرسانهای باعث شده تا افقهای جدیدی در حوزههایی مانند بینایی رایانهای، واقعیت افزوده و تعامل بین انسان و ماشین به روی ما گشوده شود.
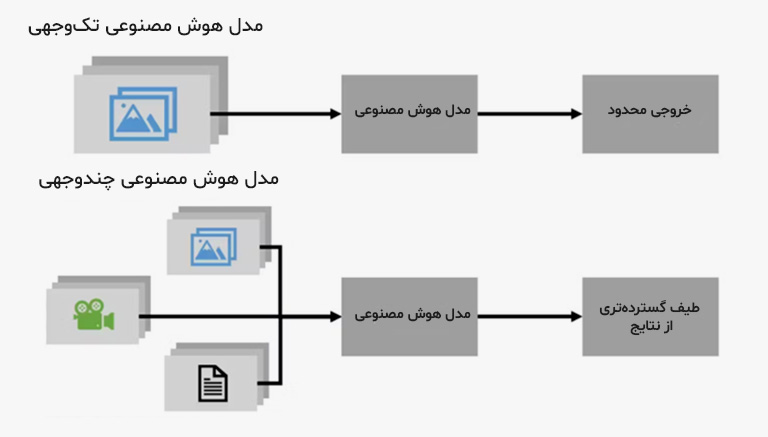
مدلهای کدنویسی (Code Models)
مدلهای کدنویسی بهطور خاص برای تحلیل، تولید و درک کدهای برنامهنویسی طراحی شدهاند و عموماً توسط برنامهنویسان مورد استفاده قرار میگیرند. برخلاف مدلهای متنی عمومی، این مدلها روی دادههایی شامل زبانهای برنامهنویسی مانند Python، JavaScript، C++ و… آموزش میبینند و هدف آنها، انجام وظایفی نظیر تکمیل خودکار کد (Code Completion)، رفع اشکال (Debugging)، توضیح کد (Code Explanation) و حتی نوشتن کدهای جدید از روی توصیفات متنی است. از جمله این مدلها میتوان به Codex، CodeBERT و AlphaCode اشاره کرد که به طور تخصصی برای کاربردهای برنامهنویسی طراحی شدهاند.
با توجه به ساختار نحوی و معنایی خاص زبانهای برنامهنویسی، این مدلها نیازمند معماری ویژهای برای درک بهتر روابط منطقی و سلسلهمراتبی کدها هستند. مدلهای کدنویسی در توسعه نرمافزار، آموزش برنامهنویسی و کمک به برنامهنویسان در محیطهای حرفهای مورد استفاده قرار میگیرند و توانستهاند در افزایش بهرهوری تیمهای توسعه، تأثیر فوقالعادهای از خود به جای بگذارند.

بر اساس کاربرد تخصصی
مدلهای زبانی برای کاربردهای مختلفی مورد استفاده قرار میگیرند. در ادامه، این مدلها را بر اساس نوع کاربری دستهبندی میکنیم.
مدلهای عمومی (General-Purpose Language Models)
مدلهای زبانی عمومی برای استفاده در طیف گستردهای از وظایف طراحی شدهاند و معمولاً بر پایه مجموعهدادههای متنوع و بزرگ آموزش میبینند. این مدلها توانایی انجام فعالیتهای مختلفی از جمله تولید متن، پاسخگویی به سؤالات، خلاصهسازی، ترجمه و تحلیل احساسات را دارند. از آنجا که دامنه آموزش آنها محدود به یک حوزه خاص نیست، از انعطافپذیری بالایی برخوردارند و در بسیاری از سناریوهای عمومی، عملکرد قابلقبولی دارند.
با این حال، همین گستردگی دامنه ممکن است باعث شود که مدل در مواجهه با مسائل تخصصی، عملکرد مورد انتظاری از خود به نمایش نگذارد. به همین دلیل، استفاده از این مدلها در حوزههای حساس مانند پزشکی یا حقوق ممکن است نیازمند نظارت انسانی یا ترکیب با منابع تخصصی دیگر باشد. مدلهای عمومی همچنان ستون فقرات بسیاری از سیستمهای هوشمند زبانی هستند و نقطه شروع خوبی برای توسعه نرمافزارهای پردازش زبان طبیعی به شمار میآیند.
مدلهای تخصصی (Domain-Specific Models)
بر خلاف مدلهای عمومی، مدلهای تخصصی برای انجام وظایف در یک حوزه خاص آموزش میبینند. این مدلها در مرحله یادگیری از دادههای تخصصی همان حوزه، مانند متون پزشکی، اسناد حقوقی، دادههای مالی یا متون علمی مهندسی و… استفاده میکنند و در مواجه با مسائل کارشناسانه و درک اصطلاحات فنی، بسیار دقیقتر از مدلهای عمومی عمل میکنند.

مدلهای تخصصی در صنایع حساس که دقت و تخصص در اولویت اول است، کاربرد فراوانی دارند. بهعنوان مثال، یک مدل زبانی آموزشدیده بر پایه دادههای پزشکی میتواند در تشخیص اولیه بیماری، تحلیل سوابق بیمار و یا تولید گزارشهای پزشکی مفید ظاهر شود. با این حال، به دلیل محدودیت دامنه کاربردی آنها، ممکن است در پاسخ به مسائل عمومی یا خارج از حوزه تخصصی خود، عملکرد ضعیفتری نسبت به مدلهای عمومی داشته باشند.
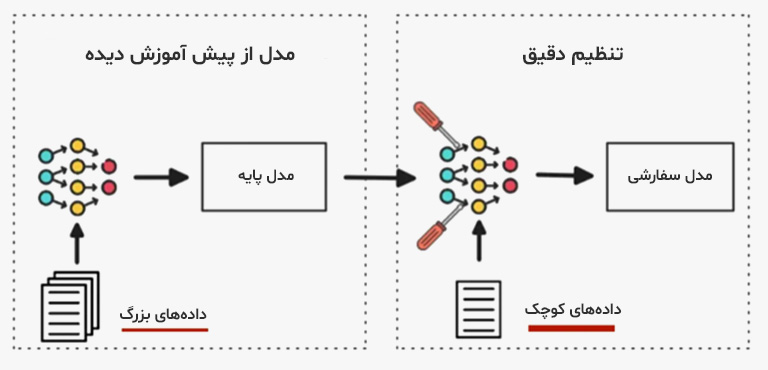
مدلهای سفارشی (Custom or Fine-Tuned Models)
مدلهای سفارشی نتیجه تنظیم دقیق (Fine-Tuning) مدلهای عمومی یا تخصصی برای پاسخگویی به نیازهای خاص یک سازمان یا پروژه هستند. در این رویکرد، مدل پایه با استفاده از دادههای خاص یک حوزه یا سازمان، مجدداً آموزش میبیند تا با سبک زبان، واژگان خاص و اهداف تعریفشده آن مجموعه هماهنگ شود. این کار باعث میشود دقت و کارایی مدل در اجرای وظایف خاص بهطور چشمگیری افزایش یابد.
مدلهای سفارشی در کسبوکارهایی که نیاز به پاسخگویی هوشمند، تولید محتوای خاص یا پشتیبانی از فرایندهای داخلی دارند، کاربرد بسیاری دارد. چتباتهایی که بر پایه این مدلهای فاینتیون شده توسعه پیدا میکنند، به چارچوبها و اصطلاحات و خاص یک سازمان مسلط هستند و قادرند به شیوهای موثر با کاربران تعامل کنند. به لطف معماریهای مدرن و ابزارهای متنباز، فرایند فاینتیونینگ نسبت به گذشته سادهتر شده و امکان توسعه مدلهای هوشمند شخصیسازیشده را برای طیف گستردهتری از کسبوکارها فراهم کرده است.
بر اساس نوع دسترسی
در این بخش، مدلهای زبانی را بر مبنای نوع دسترسی کلی تقسیمبندی میکنیم و هرکدام را به صورت مجزا مورد بررسی قرار میدهیم.
مدلهای متنباز (Open-Source Language Models)
مدلهای متنباز به مدلهایی اطلاق میشود که کد منبع، پارامترها یا وزنهای آموزشدیدهشان برای عموم در دسترس است. به طور معمول، این دسته از مدلها توسط پژوهشگران یا شرکتهایی منتشر میشوند که هدف آنها، فراهمسازی امکان توسعه، تحلیل و بومیسازی برای کاربران و محققان در سراسر جهان است. این مدلها باعث شدهاند جامعه تحقیقاتی به ابزارهای موردنیاز برای پیادهسازی ایدههای خود دسترسی داشته باشد و دست آنها برای نوآوری بیشتری در حوزه هوش مصنوعی و پردازش زبان طبیعی باز باشد. از جمله قدرتمندترین مدلهای متنباز میتوان به LLaMA، Mistral و BLOOM اشاره کرد. ویژگی اصلی این مدلها در انعطافپذیری و قابلیت سفارشیسازی آنها نهفته است.

با استفاده از این مدلها، توسعهدهندگان این امکان را دارند تا مدلهای مورد نظر خود را روی دادههای خاص، تنظیم مجدد کنند (فاینتیونینگ)، تغییرات ساختاری اعمال کنند و یا حتی مدل خود را در محیطی آفلاین و امن به اجرا درآورند. با این حال، استفاده از مدلهای متنباز ممکن است نیازمند تخصص فنی بالا، منابع محاسباتی قابل توجه و رعایت مجوزهای مربوطه باشد که بسته به نوع پروژه، میبایست به آنها توجه کرد.
مدلهای اختصاصی (Proprietary Language Models)
در ساختار مدلهای اختصاصی، کاربران تنها از طریق واسطهای تعیینشده توسط شرکت مالک میتوانند به قابلیتهای مدل دسترسی پیدا کنند و اطلاعات مربوط به پارامترها یا ساختار درونی مدل معمولاً محرمانه باقی میماند. این مدلها معمولاً توسط شرکتهای بزرگ فناوری مانند OpenAI، Anthropic یا گوگل توسعه پیدا میکنند و از طریق بسترهایی مثل API در دسترس کسبوکارها قرار میگیرند. مزیت اصلی مدلهای اختصاصی در پایداری، مقیاسپذیری و پشتیبانی رسمی آنهاست. مدلهای متنباز معمولاً با قدرت پردازشی بالا در زیرساخت ابری شرکت میزبان اجرا میشوند و کاربران نهایی نیازی به مدیریت پیچیدگیهای فنی یا تأمین منابع محاسباتی ندارند. از سوی دیگر، محدودیت در دسترسی به تنظیمات درونی، نگرانیهای مربوط به حفظ حریم خصوصی دادهها و وابستگی به ارائهدهنده از جمله چالشهای اصلی این مدلها محسوب میشود.
مدلهای بومیسازیشده یا خودمیزبان (Self-hosted Language Models)
سازمانها و کاربران میتوانند مدلهای مدنظر خود را بر روی زیرساختهای خصوصی و درونسازمانی اجرا کنند که این مدلها را به اصطلاح خودمیزبان (Self-hosted) مینامند. این مدلها میتوانند متنباز باشند یا با مجوز خاصی از مدلهای اختصاصی به اجرا در بیایند. چنین مدلیهایی اغلب در شرکتهایی با ملاحظات امنیتی، مقررات سختگیرانه یا نیاز به عملکرد آفلاین مورد استفاده قرار میگیرند تا کنترل کاملی روی محیط اجرا و دادهها داشته باشند.
اجرای مدل در زیرساخت بومی این امکان را فراهم میکند که دادهها از محیط سازمان خارج نشوند، عملکرد مدل شخصیسازی شود و اتصال به اینترنت الزامی نباشد. با این حال، این رویکرد نیازمند تخصص مهندسی بالا، زیرساخت قدرتمند سختافزاری و دانش لازم برای بهینهسازی عملکرد و نگهداری مداوم است. مدلهای خودمیزبان در صنایع حساس مانند سلامت، بانکداری و ارگانهای دولتی جایگاه ویژهای دارند و امروزه بسیار مورد استفاده قرار میگیرند.

بر اساس نوع یادگیری
آموزش مدلهای زبانی به روشهای گوناگونی صورت میگیرد و نوع یادگیری، یکی از روشهای متداول برای دستهبندی مدلهای زبانی است. در ادامه، با برخی از پرکاربردترین روشهای یادگیری مدلهای زبانی آشنا میشویم.
یادگیری با نظارت (Supervised Learning)
یادگیری نظارتشده یکی از رایجترین روشهای آموزش مدلهای زبانی است که در آن، هر نمونه از داده ورودی با یک پاسخ صحیح مرتبط میشود. هدف مدل در این نوع یادگیری، آموختن ارتباط دقیق و صحیح بین ورودی و خروجی است؛ برای مثال، در یک مدل ترجمه ماشینی، جملهای به زبان مبدأ بهعنوان ورودی و ترجمه آن به زبان مقصد بهعنوان برچسب استفاده میشود. از طریق کمینهسازی خطا میان خروجی مدل و پاسخ درست، مدل میتواند پارامترهای خود را بهتدریج بهینهسازی کند.
بیشتر بخوانید: یادگیری بانظارت چیست؟
مزیت اصلی یادگیری با نظارت، دقت بالای این مدلها در انجام وظایف خاص است؛ به طوری که معمولاً در صنایع حساسی مانند پزشکی، مالی، حقوقی و… از مدلهای یادگیری با ناظر استفاده میشود. از طرفی، این مدلها چندان بینقص نیستند و به دلیل وابستگی شدید به دادههای برچسبگذاریشده، عملکرد مناسبی در پاسخ به سؤالات عمومی ندارند. این روش، قابلیت کنترل بالا و ارزیابی عملکرد مستقیم را در اختیار کاربران قرار میدهد و از این منظر، همچنان انتخاب نخست بسیاری از توسعهدهندگان بهحساب میآید.
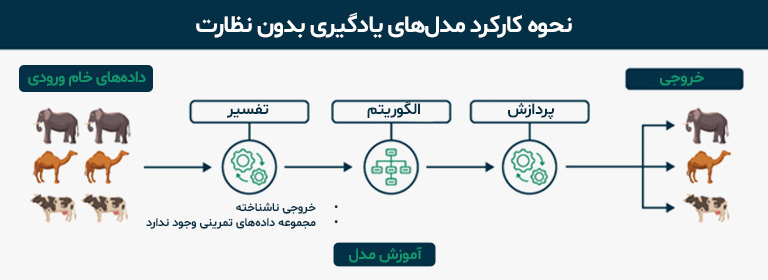
آموزش بدون نظارت (Unsupervised Learning)
در یادگیری بدون نظارت، مدل بر روی دادههای خام و بدون برچسب آموزش میبیند تا ساختارهای پنهان یا الگوهای آماری را استخراج کند. مدلهای زبانی مانند BERT در مرحله پیشآموزش از این روش استفاده میکنند و میتوانند از این طریق، بدون نیاز به پاسخهای صریح انسانی، به درک عمیقتری از زبان دست پیدا کنند.
بیشتر بخوانید: یادگیری بدون نظارت چیست؟
از مزایای اصلی این روش، امکان استفاده از حجم وسیعی از دادههای بدون برچسب در سطح اینترنت است که هزینه آموزش را بهمراتب کاهش میدهد. با این حال، نبود معیارهای صریح برای ارزیابی کیفیت خروجیها، چالشی مهم در مسیر توسعه مدلهای بدون نظارت محسوب میشود. این روش اغلب بهعنوان مرحله پایه در آموزش مدلهای زبانی مورد استفاده قرار میگیرد تا در مراحل بعدی، با روشهای نظارتشده یا فاینتیون تکمیل شود.
یادگیری تقویتی (Reinforcement Learning)
یادگیری تقویتی مبتنی بر مفهوم تعامل میان عامل (Agent) و محیط است. در این رویکرد، مدل با انجام کنشهایی در محیط، بازخورد یا پاداش دریافت میکند و تلاش میکند به سیاستی بهینه برای بیشینهسازی پاداش کل در طول زمان دست پیدا کند. در حوزه مدلهای زبانی، این تکنیک بهویژه در مرحله تنظیم رفتاری (مثل RLHF: Reinforcement Learning from Human Feedback) مورد استفاده قرار میگیرد و از طریق بازخورد عامل، میآموزد که پاسخهایی طبیعیتر، دقیقتر یا اخلاقیتر ارائه دهد.
یادگیری تقویتی در افزایش کیفیت تعاملات انسانی با مدل، بهویژه در چتباتها و سامانههای تولید متن، نقشی کلیدی ایفا میکند. با این حال، پیچیدگی پیادهسازی، زمان آموزش طولانی و دشواری در تعریف تابع پاداش مناسب، از جمله چالشهای اساسی این روش محسوب میشوند. با وجود این محدودیتها، یادگیری تقویتی توانسته به جایگاه مهمی در آموزش مدلهای بزرگ زبان، بهویژه بعد از مرحله پیشآموزش دست پیدا کند.
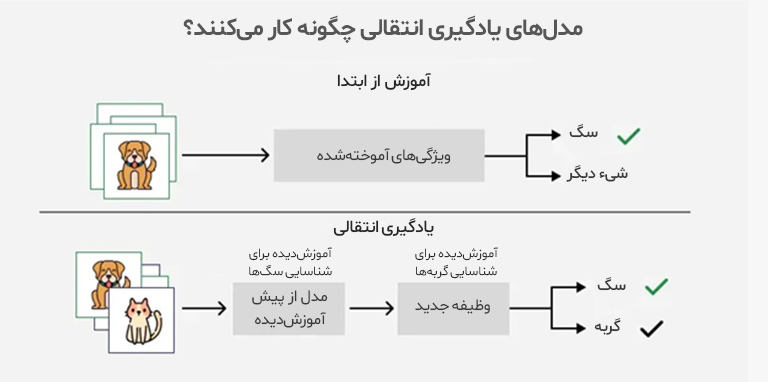
یادگیری انتقالی (Transfer Learning)
در روش یادگیری انتقالی، مدل ابتدا با استفاده از دادههای عمومی و حجیم آموزش داده میشود و سپس در مرحله بعدی، برای یک وظیفه خاص با دادههای محدودتر مجدداً تنظیم (Fine-tune) میشود. این رویکرد بهویژه در آموزش مدلهای زبانی بزرگ مانند BERT، T5 یا GPT مورد استفاده قرار میگیرد؛ چرا که امکان استفاده مجدد از دانش قبلی مدل برای حل مسائل خاصتری مانند تحلیل احساسات، پرسش و پاسخ یا ترجمه تخصصی را فراهم میکند.
مزیت کلیدی این روش در صرفهجویی منابع، زمان و دادههای آموزشی است. یادگیری انتقالی همچنین امکان استفاده از مدلهای عمومی در حوزههای تخصصی مانند پزشکی، حقوق یا مالی را فراهم کرده و موجب افزایش دقت و عملکرد مدلها در حوزههای خاص شده است. به همین دلیل، امروزه این رویکرد، یکی از ارکان اصلی طراحی مدلهای زبانی به حساب میآید.
یادگیری تطبیقی یا پیوسته (Continual Learning)
یادگیری تطبیقی (که از آن تحت عنوان یادگیری پیوسته هم نام برده میشود) به مدلها این امکان را میدهد که در طول زمان و بدون نیاز به آموزش مجدد کامل، دانش جدید کسب کرده و خود را با دادهها یا وظایف جدید تطبیق دهند. برخلاف روشهای کلاسیک که در مواجهه با دادههای جدید دچار فراموشی «دانش قبلی» میشوند (پدیده Catastrophic Forgetting)، در این روش، مدل تلاش میکند بین حفظ اطلاعات گذشته و یادگیری دادههای جدید توازن برقرار کند.
این نوع یادگیری برای سیستمهایی که در معرض دادههای متغیر یا پویا، مثل دستیارهای مجازی یا سیستمهای تحلیل بازار قرار دارند، بسیار کارآمد است. همچنین در شرایطی که دادهها بهصورت پیوسته و به مرور زمان در دسترس قرار میگیرند، مدلهای یادگیرنده پیوسته میتوانند عملکرد بهینهتری نسبت به مدلهای ایستا داشته باشند.
دنیای پویای مدلهای زبانی، همواره در حال پیشرفت و دگرگونی است. گاهی برخی از روشهای اشارهشده با یکدیگر ادغام میشوند و شکل تازهای از مدلهای زبانی را پدید میآورند، گاهی با پیادهسازی تکنیکهای خاص، بهرهوری مدلهای موجود بهبود پیدا میکند و گاهی با روی کار آمدن یک فناوری بهروز، نوع جدیدی از مدلهای زبانی هم روی کار میآیند. مسیر رشد مدلهای زبانی، هنوز در ابتدای مسیر خود قرار دارد.
معرفی بهترین مدلهای زبانی بزرگ (Large Language Models)
تا به اینجا، با سازوکار و نحوه فعالیت مدل زبانی بزرگ (LLM) آشنا شدهایم. در این بخش، به بررسی برخی از بهترین مدلهای زبانی بزرگ میپردازیم و کاربردهای آنها را مرور میکنیم.
۱. (GPT (Generative Pre-trained Transformer
مدل GPT، یکی از برجستهترین و پرکاربردترین مدلهای زبانی بزرگ است که توسط مجموعه OpenAI توسعه یافته است. این مدل، مبتنی بر شبکههای عصبی ترنسفورمر توسعه پیدا کرده و از همین رو، عملکرد خیرهکنندهای در فهم و تولید متنهای انسانی دارد. این مدل با استفاده از کلاندادههای عظیم و روش بدون نظارت آموزش دیده و بهمنظور تولید محتوا، خلاصهسازی متن، ترجمه و دیگر حوزههای مرتبط با پردازش زبان مورد استفاده قرار میگیرد.
تاکنون، نسخههای متعددی از مدل GPT در دسترس کاربران قرار گرفته است که جدیدترین آن، نسخه GPT-4 است. نسخه چهارم این مدل محبوب، دقت و تواناییهای بیشتری در درک و تولید زبان انسانی دارند و میتواند علاوهبر متن، از طریق دیگر قالبهای محتوایی مانند صوت و عکس هم با کاربران تعامل کند.
۲. Gemini
مجموعه Google DeepMind با معرفی مدل زبانی هوش مصنوعی Gemini، یکی از پیشرفتهترین LLMهای موجود را به بازار عرضه کرد. این مدل که از فناوریهای جدید یادگیری عمیق و شبکههای عصبی پیشرفته استفاده میکند، قادر به پردازش زبانهای طبیعی با دقت بالا و تولید پاسخهای معنادار است. امروزه Gemini به دلیل تواناییهای فوقالعادهاش در زمینههایی مانند تحلیل دادههای پیچیده، جستجوی عمیق میان اطلاعات موجود در اینترنت و تولید محتوای چندمنظوره شناخته میشود. Gemini به طور کامل با دیگر سرویسهای گوگل مانند Maps، Gmail، ِDocs و… سازگار است و توانسته با تبادل اطلاعات میان این سرویسها، اکوسیستمی یکپارچه و کارآمد را خلق کند.
۳. Grok
ایلان ماسک، یکی از سرمایهگذاران اصلی پروژه GPT، پس از مدتی راه خود از OpenAI جدا کرد و با تأسیس شرکت xAI، توسعه مدل زبانی اختصاصی خود را کلید زد. xAI موفق شده با توسعه مدل Grok، مدلی چندمنظوره و توانمند را توسعه دهد و جایگاه خود را در میدان رقابت LLMها تثبیت کند. Grok مانند دیگر مدلهای پیشرفته و بهروز، از محتوای چندرسانهای مانند تحلیل تصاویر، PDFها و فایلهای متنی پشتیبانی میکند و میتواند به لطف حالت Think Mode خود، به مسئلههای بسیار پیچیده و عمیق پاسخ دهد.
بیشتر بخوانید: بررسی جدید ترین نسخه هوش مصنوعی Grok3
۴. LLaMA
تا به اینجای کار، تمامی مدلهای زبانی معرفی شده در چارچوب مدلهای اختصاصی دستهبندی میشوند؛ اما حال قصد داریم به معرفی مدلی متنباز و در عین حال قدرتمند بپردازیم. با LLaMA آشنا شوید؛ دستاورد ارزشمند مجموعه Meta (فیسبوک سابق) در زمینه مدلهای بزرگ زبانی که نقشی تاثیرگذار در دسترسی عمومی به LLMها ایفا کرد.
این نسخه در نسخهها و مقیاسهای متنوعی در دسترس توسعهدهندگان قرار گرفته و کسی این امکان را دارد تا با توجه به نیاز و سختافزار خود، یکی از نسخههای لاما را انتخاب کند. نسخه سوم این مدل توانست به محبوبیت فوقالعادهای دست پیدا کند و توسط تعداد بیشماری از توسعهدهندگان و کسبوکارها مورد استفاده قرار گرفت. نسخه چهارم LLaMA نیز بهتازگی عرضه شده و موفق شده از لحاظ عملکرد، پا را از نسخههای پیشین خود هم فراتر بگذارد. تمامی نسخههای این ال ال ام جذاب هماکنون بهصورت متنباز و رایگان در دسترس است و شما میتوانید از حالا استفاده از آنها را آغاز کنید.
۵. DeepSeek
طی سالهای اخیر، استارتاپهای چینی توانستهاند جهشی چشمگیر در عرصه مدلهای زبانی رقم بزنند و بهعنوان رقیبی قابل اعتنا برای مدلهای مشهور آمریکایی و اروپایی شناخته شوند. یکی از این استارتاپها، DeepSeek است که با عرضه مدل زبانی بزرگ خود، انقلابی بزرگ در دنیای LLMها رقم زد. مدل DeepSeek با بهینهسازی شیوه آموزش مدل، توانست تا %90 در مصرف منابع صرفهجویی کند و با زیرساختهایی به مراتب کمتر، عملکردی همپای برترین مدلهای زبانی بزرگ از خود به نمایش بگذارد.

معرفی مدلهای بزرگ زبانی فارسی
اکوسیستم هوش مصنوعی فارسی طی سالهای گذشته، پیشرفت قابل توجهی داشته و توانسته در بسیاری از زمینهها از جمله مدلهای زبانی حرفهای زیادی برای گفتن داشته باشد. در این بخش، شماری از برترین مدلهای زبانی فارسی را معرفی و بررسی میکنیم.
۱. گروه مدل زبانی «درنا»
مرکز تحقیقات هوش مصنوعی پارت به عنوان یکی از مجموعههای پیشرو ایران در توسعه مدلهای زبانی فارسی، چند نمونه از کاربردیترین مدلهای زبانی مبتنی بر زبان فارسی را در قالب گروه مدل زبانی درنا در اختیار زیستبوم هوش مصنوعی کشور قرار داد. این مدلها در ظرفیتهای 3، 7 و 13 میلیارد پارامتر عرضه شدهاند و اکنون به صورت متنباز در دسترس کاربران فارسیزبان قرار دارند. درنا به منظور ارائه پاسخهای دقیق به پرسشهای فارسی طراحی شده و در زمینههایی مانند تولید محتوا، ترجمه ماشینی و تحلیل متون کاربرد فراوانی دارد.
۲. شیراز
مدل زبانی شیراز، محصولی از شرکت دانشبنیان لایفوب است و بر پایه معماری MobileBERT توسعه پیدا کرده است. این مدل شامل بیش از 25 میلیون پارامتر است و از این لحاظ، در دسته مدلهای سبک و کمحجم جای میگیرد. مدل شیراز با تمرکز بر سرعت پاسخگویی بالا ساخته شده و هماکنون به صورت کاملاً متنباز و رایگان در دسترس علاقهمندان قرار دارد.
۳. توکا
مدل زبانی توکا، از دیگر مدلهایی است که توسط مرکز تحقیقات هوش مصنوعی پارت توسعه پیدا کرده و به صورت متنباز در دسترس قرار گرفته است. توکا بر مبنای معماری BERT ساخته شده و پیشرفت چشمگیری در درک زبان طبیعی فارسی نسبت به مدل پایه خود دارد. این مدل زبانی توانسته در زمینه درک مطلب، کیفیت چندانتخابی و بهبود کلی، امتیازات بالایی کسب کند و از همین رو، به عنوان یکی بهینهترین مدلهای زبانی فارسی شناخته شود.
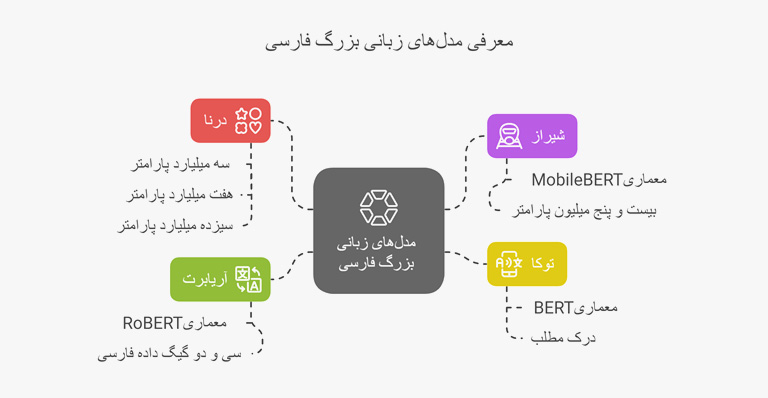
۴. آریابرت
آریا برت، یک مدل فارسی از پیش آموزش دیده است که برای تقویت وظایف پردازش زبان طبیعی در حوزه زبان فارسی طراحی شده است. این مدل مبتنی بر معماری RoBERT توسعه پیدا کرده که به دلیل کاراییاش در انجام وظایف NLP کاربرد دارد. این مدل بر روی بیش از 32 گیگ داده فارسی آموزش دیده و توانایی مناسبی در درک و تولید متن به زبان فارسی دارد.
هرچند که مدلهای زبانی فارسی هنوز در ابتدای مسیر خود قرار دارند؛ اما شروع این مسیر با گامهای بلندی همراه بوده و انتظار میرود در آینده نه چندان دور، شاهد پیشرفتهایی بهمراتب فراتر از گذشته در این حوزه باشیم.
نتیجهگیری
مدلهای زبانی فقط ابزارهایی برای تولید متن نیستند؛ آنها نقش پلی میان زبان انسانی و زبان ماشینها را ایفا میکنند. این مدلها، درک ما از هوش مصنوعی را دگرگون کردهاند و مسیر تازهای برای تعامل انسان و فناوری گشودهاند. بیتردید در سالهای پیش رو، مدلهای زبانی در کنار پیچیده شدن، بیش از پیش جایگاه خود را در زندگی روزمره ما تثبیت میکنند؛ گاهی بهعنوان دستیار، گاهی آموزگار و شاید حتی روزی بهعنوان یک دوست و همصحبت قابل اعتماد. باید منتظر ماند و دید آینده فناوری هوش مصنوعی، این ابزار تحولآفرین را به کدام سو سوق میدهد.








