تصور کنید بهجای تایپ کردنهای خستهکننده، تنها با صحبتکردن، نوشتهای روان، دقیق و آماده انتشار در اختیار داشته باشید. در دهههای گذشته، چنین تصوری دور از انتظار به نظر میرسید؛ اما پیشرفتهای فناورانه و ظهور ابزارهای «تبدیل گفتار به متن» توانست به این رویای دیرینه رنگ واقعیت ببخشد. در این مطلب، چگونگی کارکرد سرویسهای گفتار به متن را بررسی میکنیم تا ببینیم چگونه ماشینهای امروزی میتوانند به لطف این فناوری جذاب، مانند یک انسان واقعی بشنوند، گفتار را درک کنند و نتیجه را به متنی روان تبدیل کنند.
سرویس صوت به متن چیست؟
سرویس صوت به متن (Speech-to-Text) که از آن تحت عنوان گفتار به متن هم یاد میشود، یک فناوری مبتنی بر پردازش سیگنال و هوش مصنوعی است که گفتار انسان را بهصورت خودکار به متن نوشتاری تبدیل میکند. سیستم کامپیوتری در این فرایند، امواج صوتی تولیدشده توسط گوینده را دریافت میکند و با استفاده از الگوریتمهای زبانی، آنها را به کاراکترها، کلمات و عبارات دیجیتال تبدیل میکند.

در یک سرویس صوت به متن، ورودی معمولاً یک فایل یا گفتگوی زنده است که میتواند از طریق میکروفون، تماس تلفنی یا فایل ضبطشده به سیستم ارائه شود. سرویس Speech to Text در ابتدا سیگنال صوتی را به قطعات کوچک تقسیم میکند و سپس با استفاده از مدلهای زبانی، الگوهای واجها و کلمات را تشخیص میدهد. نتیجه این فرایند، متنی است که با دقتی بالا از روی گفتار اولیه به نگارش درآمده است.
بیشتر بخوانید: مقایسه بهترین APIهای Speech-to-Text در سال ۲۰۲۵
پیشرفتهای حاصل از یادگیری ماشین، یادگیری عمیق و مدلهای زبانی بزرگ مانند GPT باعث شدهاند دقت و کارآمدی سرویسهای صوت به متن به طور قابلملاحظهای افزایش پیدا کند. این الگوریتمها با تحلیل حجم عظیمی از دادههای صوتی و متنی، میتوانند الگوهای موجود در زبان گفتاری را شناسایی کنند و دقت تشخیص را حتی در شرایط چالشبرانگیز مانند وجود نویز یا تنوع لهجه، بالا ببرند.
به طور خلاصه، سرویس تبدیل صوت به متن نقش پلی میان گفتار انسان و نوشتار را ایفا میکند که با بهرهگیری از پیشرفتهترین فناوریهای پردازش زبان و یادگیری ماشینی، ارتباط انسان و ماشین را سادهتر و هوشمندتر میکند.
تاریخچه مدلهای گفتار به متن؛ از دهه 50 میلادی تا سلطه هوش مصنوعی
هرچند فناوری تبدیل گفتار به متن طی سالهای اخیر پیشرفت چشمگیری داشته و شرکتهایی مانند گوگل موفق شدهاند از مرز دقت 98 درصدی هم عبور کنند، اما این فناوری، مسیر طولانی و پر فرازونشیبی را طی کرده تا امروز به گوشیهای هوشمند، دستیارهای صوتی، کامپیوترهای شخصی و… راه پیدا کند.
در این بخش، نگاهی مختصر به سیر تحول فناوری تشخیص گفتار میاندازیم تا ببینیم که چگونه این فناوری از یک ایده آزمایشگاهی ساده به ابزاری فراگیر و روزمره تبدیل شد. مسیر تحول آن را میتوان به چند دوره کلیدی تقسیم کرد:
دهه 1950 و 60 میلادی؛ آغاز پیدایش
برای شروع، میبایست به سال 1952 برگردیم؛ زمانی که آزمایشگاه Bell با ساخت دستگاهی به نام «Audrey» توانست اولین ماشین تشخیص گفتار را خلق کند. این ماشین قادر بود اعداد و ارقامی که یک گوینده بیان میکرد را تشخیص دهد و آن را در سیستم خود پردازش کند. ده سال زمان برد تا IBM با معرفی «Shoebox» به دنیای کلمات وارد شود و رویای تبدیل خودکار کلمات به متن را به واقعیت نزدیک کند.
سیستم Shoebox این امکان را داشت که تا 16 کلمه انگلیسی را شناسایی کند. شاید این رقم در حال حاضر ناچیز به نظر برسد؛ اما با توجه به قدرت پردازش و دادههای قابل دسترس در بیش از نیم قرن پیش، این مقدار یک تحول شگفتیآفرین به حساب میآمد.

دهه 1970 و 80 میلادی؛ ظهور مدلهای آماری
در اوایل دهه 1970 میلادی، آژانس DARPA آمریکا به توجه ویژه به فناوری تبدیل گفتار به متن، بزرگترین پروژه تحقیقاتی در زمینه درک گفتار را تحت عنوان «Speech Understanding Research» آغاز کرد. حاصل این پروژه، توسعه سیستم «Harpy» توسط دانشگاه کارنگی ملون بود که میتوانست تا 1000 واژه مختلف را شناسایی کند. این رقم در زمان خود فوقالعاده به نظر میرسید؛ چرا که این تعداد کلمه معادل دایره واژگان یک کودک سه ساله است.
بیشتر بخوانید: مقایسه و انتخاب بهترین ای پی آی های متن به صوت
با گسترش قدرت محاسباتی، پژوهشگران به سمت مدلهای آماری مانند مدلهای مارکوف پنهان (HMM) رفتند. این مدل به جای تکیه صرف بر الگوهای صوتی، احتمال اینکه یک صدای ناشناخته به یک واژه خاص تعلق داشته باشد را محاسبه میکرد. به لطف این روش، سیستمها توانستند هزاران واژه مختلف را شناسایی و پردازش کنند.
دهه 1990 میلادی؛ قدرتگرفتن کامپیوترهای شخصی
با ظهور کامپیوترهای شخصی و پردازندههای قدرتمند در دهه 1990 میلادی، نرمافزارهایی مانند Dragon Dictate وارد بازار شدند و از این طرق، فناوری تشخیص گفتار به خانهها راه پیدا کرد. در همین میان، شرکت BellSouth با معرفی سیستم تعاملی VAL، یک پاسخگویی تلفنی را به بازار عرضه کرد که به نوعی پایهگذار سیستمهای پاسخگوی تلفنی امروزی محسوب میشود.
دهه 2000 میلادی؛ انقلاب گوگل به لطف کلاندادهها
تا پیش از سال 2001، دقت سیستمهای تشخیص صوت به 80% رسیده بود که برای بهبود، به حجم زیادی از دادهها نیاز داشت؛ گنجینهای که تنها شرکتهای انگشتشماری به آن دسترسی داشتند. یکی از این مجموعهها که به لطف موتور جستجوی پرمخاطب خود، به بانکی از کلاندادهها شامل 230 میلیارد واژه دسترسی داشت، شرکت نام آشنای گوگل بود. این مجموعه با معرفی قابلیت «Google Voice Search»، نهتنها از طریق انتقال مرکز پردازش به سرورهای خود، دقت سیستمهای گفتار به متن را چندین پله ارتقا داد، بلکه این ابزار کاربردی را به دست میلیونها کاربر خود در سراسر جهان رساند و بهنوعی، فناوری صوت به متن را فراگیر کرد.
دهه 2010 میلادی؛ عصر هوش مصنوعی
در سال 2011، شرکت اپل هم با عرضه دستیار صوتی Siri، به میدان رقابت مدلهای تشخیص صوت پیوست. پس از Siri، دستیارهای صوتی بسیاری مانند Alexa، Google Home، کورتانا و… روی کار آمدند و با دقت فوقالعاده خود، صحبت با ماشینها را به امری روزمره تبدیل کردند. پیشرفت در شبکههای عصبی عمیق، بهویژه ظهور معماری ترنسفورمر، نقطهٔ عطفی در حوزه تبدیل گفتار به متن بود؛ بهگونهای که مدلهای گفتار به متن امروزی با استفاده از این معماری، نهتنها قادر به بازشناسی دقیق واژگان هستند، بلکه میتوانند با در نظر گرفتن بافت مکالمه، منظور و مقصود گوینده را هم پیشبینی و تفسیر کنند.
آینده فناوری تبدیل گفتار به متن
با دسترسی بیشتر به مدلهای مبتنی بر هوش مصنوعی، انتظار میرود در آینده نزدیک، افراد بیشتری به ارتباط گفتاری با ماشینها روی بیاورند. این تحول نهتنها تجربه کاربری را سادهتر و طبیعیتر میکند، بلکه باعث میشود تعامل با فناوری برای افرادی که محدودیتهای حرکتی یا دیداری دارند نیز بسیار آسانتر شود.
پیشرفت در مدلهای زبانی و پردازش گفتار باعث خواهد شد سیستمها بتوانند لهجهها، زبانهای محلی و حتی احساسات و لحن گوینده را با دقت بالاتری تشخیص دهند. درنتیجه، دستگاهها نهتنها کلمات را خواهند فهمید، بلکه زمینه، نیت و حتی حالت روحی ما را نیز درک خواهند کرد.
انتظار میرود این فناوری در آینده به شکلی یکپارچه در ابزارهای پوشیدنی، خودروها، لوازم خانگی هوشمند و حتی محیطهای کاری مجازی ادغام شود. در چنین جهانی، تایپکردن و استفاده از رابطهای سنتی ممکن است بهتدریج جای خود را به گفتوگوهای طبیعی با ماشینها بدهد و مرز میان ارتباط انسانی و ماشینی بیش از هر زمان دیگری کمرنگ شود.
سرویس تبدیل صوت به متن چگونه کار میکند؟
در این بخش، فرایند تبدیل گفتار به نوشتار را گامبهگام بررسی میکنیم تا ببینیم چگونه واژههای بیانشده، مسیر خود را طی میکنند تا در نهایت بهصورت متن بر صفحهنمایش ظاهر شوند.
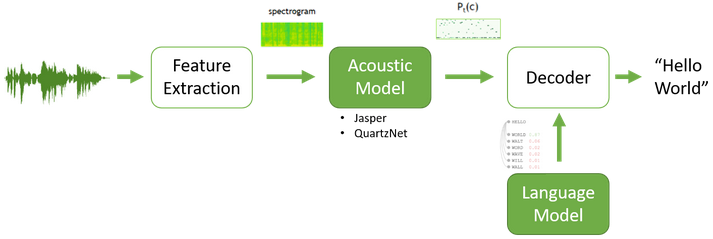
1. دریافت ورودی صوتی (Speech Input)
فرایند تبدیل صوت به متن با ضبط گفتار کاربر توسط میکروفون آغاز میشود. این صدا میتواند بهصورت زنده (همزمان با صحبت) و یا از یک فایل ضبطشده به سیستم وارد شود.
2. پیشپردازش صدا (Audio Preprocessing)
پس از ضبط، صدا وارد مرحله پیشپردازش میشود تا کیفیت آن بهبود پیدا کند. این کار شامل حذف نویز پسزمینه، فیلترکردن فرکانسهای غیرضروری، تنظیم و یکسانسازی حجم صدا، تقسیمبندی کلیپ صوتی برای پردازش آسانتر و تبدیل فایل به یک فرمت استاندارد است.
3. استخراج ویژگیها (Feature Extraction)
در این مرحله، نرمافزار ویژگیهای منحصربهفرد صدا مانند زیر و بم (Pitch)، الگوهای تکراری و ساختار آوایی را شناسایی میکند. سیگنال صوتی معمولاً به شکل طیفنگار (Spectrogram) نمایش داده میشود که نمایانگر توزیع فرکانسها در طول زمان است. در ادامه، صدا به واجها (Phonemes) که کوچکترین واحد گفتاری هستند، تجزیه میشوند تا کار پردازش راحتتر انجام شود.
4. تطبیق با مدل زبانی (Decoding)
در این مرحله، واجهای استخراجشده در مرحله قبل مورد تجزیهوتحلیل قرار میگیرد. الگوریتمهای یادگیری عمیق پیشبینی میکنند که هر واج به کدام حرف یا کلمه تعلق دارد و چگونه این کلمات در جمله کنار هم قرار میگیرند. مدلهای زبانی این امکان را دارند که بر اساس بافت (Context) متن، کلمه بعدی را پیشبینی کنند و از این طریق، خطاهای احتمالی را به حداقل برسانند.
5. خروجی متن نهایی (Word Output)
در نهایت، متن تولیدشده با اضافهکردن علائم نگارشی، فاصله و نیمفاصله و… قالببندی میشود تا ایرادات آن رفع و به متنی استاندارد تبدیل شود.
روشهای تبدیل گفتار به متن
معمولا برای تبدیل صوت به متن از سه روش اصلی استفاده میشود:
- تشخیص همزمان (Synchronous Recognition)
در این روش، گفتار بلافاصله و بهطور مستقیم به متن تبدیل میشود. این روش اغلب برای زیرنویس کلیپهای کوتاه و یا مصاحبههای زنده تلویزیونی مورداستفاده قرار میگیرد. در این روش، سرویس ابتدا کل گفتار یا فایل صوتی را دریافت و پردازش میکند و سپس نتیجه را بهصورت یکجا ارائه میدهد.
- تشخیص از طریق استریم (Streaming Recognition)
تشخیص از طریق استریم هم مانند روش تشخیص همزمان، صحبت شخص یا اشخاص موردنظر را بهصورت آنی به متن تبدیل میکند؛ اما تفاوتشان در شیوه و زمانبندی پردازش نهفته است. در تشخیص استریم، پردازش صدا همزمان با صحبت کاربر انجام میگیرد و متن بهتدریج روی صفحه به نمایش در میآید. این روش بهخصوص برای مکالمات زنده، جلسات و یا سخنرانیها مفید است؛ چرا که مخاطب میتواند همزمان با شنیدن صدا، متن را نیز ببیند.
- تشخیص غیرهمزمان (Asynchronous Recognition)
تشخیص غیرهمزمان روشی است که در آن فایلهای صوتی طولانی که از قبل ضبط شدهاند، برای پردازش و رونویسی به سیستم ارسال میشوند. برخلاف روشهای همزمان یا استریم که خروجی را بلافاصله یا در حین صحبت ارائه میدهند، در این روش، فایل ممکن است در یک صف پردازش قرار بگیرد و پس از گذشت مدتی، متن نهایی آماده شود. این شیوه برای پروژههایی که نیاز به خروجی آنی ندارند (مثل رونویسی جلسات طولانی، پادکستها یا آرشیو صوتی) یک گزینه مناسب محسوب میشود و معمولاً از دقت بالاتری هم برخوردار است؛ چرا که سیستم میتواند با فراغ بال کل فایل را پردازش و اصلاحات لازم را اعمال کند.
مزایا و محدودیتهای سرویسهای صوت به متن چیست؟
سرویسهای تبدیل متن به صوت هم مانند هر ابزار دیگری مزایا و معایب مختص به خود را دارند که آشنایی با آنها میتواند به کاربر در انتخاب سرویس مناسب کمک کند. در این بخش، برخی از مزایا و معایب سرویسهای تبدیل صوت به متن را بررسی میکنیم و خواهیم دید که چگونه این ابزار کاربردی میتواند فرایندهای کاری، آموزشی و حتی فعالیتهای روزمره ما را سادهتر و کارآمدتر کند.
بیشتر بخوانید: چرا باید از سرویس تبدیل گفتار به متن استفاده کنیم؟
مزایای سرویس تبدیل صوت به متن
سرویس تبدیل صوت به متن به لطف مزایای پرشمار و درعینحال کاربردی خود، امروزه راه خود را به بسیاری از وبسایتها، اپلیکیشنها و پلتفرمهای مختلف باز کرده است. اما این مزایا چیست که تا این حد توجه توسعهدهندگان و صاحبان کسبوکار را جلب کردهاند؟ مهمترین آنها عبارتند از:
- صرفهجویی در زمان
تایپ کردنهای طولانی و خستهکننده را فراموش کنید! سرویسهای تبدیل صوت به متن به شما کمک میکنند تا تنها از طریق صحبتکردن، متن مورد نظر خود را آماده کنید. این ویژگی خصوصاً برای خبرنگاران، نویسندگان و تولیدکنندگان محتوا بسیار ارزشمند است و میتواند زمان کاری آنها را به شکل چشمگیری کاهش دهد.
- افزایش دقت و کاهش خطا
مدلهای پیشرفته هوش مصنوعی که وظیفه پشتیبانی از سرویسهای صوت به متن را بر عهده دارند، میتوانند لهجههای مختلف، گفتار سریع یا آرام و حتی اصطلاحات تخصصی هر حوزه را شناسایی کرده و آنها را به متنی دقیق و قابل اعتماد تبدیل کنند. این ویژگی باعث میشود خطاهای انسانی در تایپ به حداقل برسد و خروجی نهایی، کیفیتی بسیار نزدیک به گفتار اصلی داشته باشد.
- افزایش دسترسیپذیری
نقش سرویسهای تبدیل صوت به متن در توانمندسازی افرادی با محدودیتهای حرکتی یا مشکلات شنوایی و گفتاری چنان پررنگ است که عملاً برخی از محدودیتهای این افراد را از میان برداشته است. این فناوری امکان آن را دارد که به افرادی که قادر به تایپ طولانی نیستند یا به دلیل شرایط جسمی نمیتوانند بهراحتی از ابزارهای سنتی ارتباطی استفاده کنند، کمک کند تا محتوای خود را تنها با صحبتکردن تولید و به اشتراک بگذارند. همچنین برای افراد ناشنوا یا کمشنوا، تبدیل گفتار به متن بهصورت همزمان میتواند تجربه ارتباطی کارآمدتری فراهم کند.
- بهبود بهرهوری
پس از استفاده از سرویسهای صوت به متن در فرایندهای کاری، دیگر نمیتوان نقش این ابزار را در افزایش بهرهوری تیمها نادیده گرفت. در جلسات کاری، این فناوری امکان ذخیره خودکار و دقیق متن مذاکرات را فراهم میکند، بهطوری که اعضای تیم میتوانند بدون نگرانی از یادداشتبرداری همزمان، تمام تمرکز خود را روی بحثها و تصمیمگیریها معطوف کنند. این قابلیت به مرور و بازبینی راحتتر مباحث پس از جلسه کمک کرده و باعث میشود اطلاعات مهم به هیچ عنوان از قلم نیفتد. در نتیجه، هماهنگی تیمی بهتر شده و روند کاری سریعتر و منسجمتر پیش میرود.
- پشتیبانی از چند زبان مختلف
یکی از قابلیتهای مهم و کاربردی سرویسهای تبدیل صوت به متن، پشتیبانی از چندین زبان مختلف است. این قابلیت بهویژه برای تیمها و پروژههای بینالمللی اهمیت فراوانی دارد؛ چرا که امکان تبدیل گفتار به متن را در زبانهای گوناگون فراهم میکند و باعث میشود کسبوکارها بدون محدودیت زبانی با سازمانهای برونمرزی ارتباط برقرار کنند. این قابلیت نهتنها فرایند همکاری میان افراد با زبانهای متفاوت را سادهتر میکند، بلکه به کسبوکارها و سازمانها اجازه میدهد به بازارهای جهانی دسترسی پیدا کنند و خدمات خود را در سطح گستردهتری ارائه دهند.
محدودیتهای سرویس تبدیل صوت به متن
تا به اینجا از مزایای سرویس تبدیل صوت به متن گفتیم و کاربردهای آن را برای کسبوکارهای مختلف بررسی کردیم. با این حال، این فناوری همچنان محدودیتها و چالشهایی دارد که آشنایی با آنها به انتخاب بهتر و استفاده بهینهتر کمک میکند. در این مطلب، به مهمترین محدودیتهای سرویسهای تبدیل صوت به متن میپردازیم.
- وابستگی به کیفیت صدا
یکی از بزرگترین محدودیتهای سرویسهای تبدیل صوت به متن، خصوصاً در ابزارهای میانرده و پایینرده، وابستگی شدید این سرویسها به کیفیت فایل صوتی یا صدای ورودی است. نویز محیط، اکو، صدای پسزمینه و میکروفونهای نامرغوب میتوانند باعث کاهش دقت تشخیص گفتار شوند و در نتیجه، کیفیت متن خروجی را تحت تاثیر قرار میدهند.
- هزینههای استفاده
سرویسهای حرفهای تبدیل صوت به متن معمولاً نیازمند پرداخت هزینه اشتراک یا پرداخت بر اساس میزان استفاده هستند. این مبحث هنگام استفاده از سرویسهای خارجی که نیازمند پرداخت هزینه دلاری هستند بیشازپیش خودنمایی میکند و ممکن است برای برخی کاربران یا کسبوکارهای کوچک محدودیت مالی ایجاد کند.
- چالش در تشخیص کلمات تخصصی و اصطلاحات فنی
در حوزههای تخصصی مانند پزشکی، حقوق یا فناوری اطلاعات، اصطلاحات خاصی وجود دارد که ممکن است مدلها بهدرستی آنها را تشخیص ندهند یا اشتباه ترجمه کنند.
در مجموع، مزایای سرویسهای تبدیل گفتار به متن آنقدر گسترده و کاربردی هستند که اغلب ضعفهای احتمالی را بهخوبی پوشش میدهند؛ بهویژه در سرویسهای جدیدی که مبتنی بر الگوریتمهای پیشرفته هوش مصنوعی توسعه پیدا کردهاند و محدودیتهایشان روزبهروز کمتر میشود. با توجه به تمامی نکات بیان شده، حال میتوانید هر دو وجه مثبت و منفی این سرویسها را بر کفه ترازو بگذارید و بهترین گزینه را برای نوع فعالیت خود انتخاب کنید.
جمعبندی
فناوری تبدیل گفتار به متن از زمانی که تنها قادر بود تعداد انگشتشماری از اعداد را شناسایی کند تا به امروز که به لطف هوش مصنوعی میتواند طیف وسیعی از زبانها، گویشها و لهجهها را پوشش دهد، مسیر دور و درازی را طی کرده است. مسیری که روزبهروز تکامل پیدا کرده، از سد محدودیتها گذشته و توانسته امکان گفتگوی طبیعی با ماشینها را برای ما فراهم کند. با توجه به چشمانداز آینده این فناوری، صحبتکردن با ماشینها و رباتها، درست همانگونه که با دوستان خود گفتگو میکنیم، دیگر یک رؤیای دور از دسترس نیست و انتظار میرود بهزودی فناوری گفتار به متن به شیوه اصلی تعامل با دنیای دیجیتال تبدیل شود.








