
از زمان ظهور نخستین کامپیوترها تا اوایل قرن بیستویکم، ماشینها تنها تابعی از کدهای از پیش برنامهریزی شده بودند و در مواجهه با دادهها و وظایف جدید، کاربرد خود را از دست میدادند. در همین حین، هوش مصنوعی (AI) با یکی از فناوریهای زیرمجموعه خود، این معادله را برای همیشه تغییر داد تا ماشینها بتوانند دادههای جدید را دریافت کنند و براساس آن آموزش ببینند؛ مفهومی که امروزه آن را با نام «یادگیری ماشین» میشناسیم. در این مطلب قصد داریم به معرفی این فناوری کاربردی بپردازیم و ۱۰ نمونه از مهمترین الگوریتمهای یادگیری ماشین را بشناسیم.
یادگیری ماشین چیست؟
یادگیری ماشین (Machine learning) بیش از آن که یک شاخه از هوش مصنوعی و علوم کامپیوتری باشد، یک تحول فکری و کاربردی است که نحوه تعامل ما با دادهها و مسائل پیچیده را دگرگون میکند. بهطور خلاصه در تعریف این فناوری میتوان گفت:
«یادگیری ماشین مجموعهای از الگوریتمها و مفاهیم ریاضی است که به وسیله آنها، رایانهها بتوانند با تجزیهوتحلیل حجم زیادی از دادهها، مسائلی را یاد بگیرند و وظایف خاصی را انجام دهند.»
به عبارتی دیگر، در الگوریتمهای یادگیری ماشین به جای آنکه ما برای کامپیوترها برنامهریزی کنیم که چه کاری انجام دهند، مجموعهای از دادهها را در اختیار آنها قرار میدهیم تا خود، الگوها و روابط موجود در آنها را کشف کند و به انجام وظایف بپردازند. این فرایند شامل آموزش مدل (Model Training) با استفاده از دادههای آموزشی و سپس ارزیابی عملکرد مدل بر روی دادههای جدید است.
یادگیری ماشین را میتوان به طور کلی به سه دسته اصلی تقسیم کرد:
یادگیری نظارتشده (Supervised Learning)
در یادگیری نظارتشده، الگوریتم با دادههای برچسبدار (Labeled Data) آموزش داده میشود که شامل مجموعهای از ورودیها و خروجیهای مرتبط با یکدیگر است. هدف الگوریتم، یادگیری یک تابع است که بتواند خروجیها را بر اساس ورودیهای دریافت شده پیشبینی کند.
بیشتر بخوانید: یادگیری با نظارت چیست؟
یادگیری بدون نظارت (Unsupervised Learning)
در این نوع یادگیری، الگوریتم با دادههای بدون برچسب آموزش داده میشود. در این رویکرد، الگوریتم بهتنهایی باید الگوها، ساختارها و روابط پنهان میان دادهها را کشف کند. هدف اصلی در این نوع یادگیری، یافتن گروهبندیهای طبیعی (clustering)، کاهش ابعاد دادهها (dimensionality reduction) یا یافتن ناهنجاریها (anomaly detection) است. این روش برای دادههایی که بهخوبی برچسبگذاری نشدهاند یا در آنها خروجی مورد انتظاری در نظر نیست، بسیار مناسب است.
بیشتر بخوانید: یادگیری بدون نظارت چیست؟
یادگیری تقویتی (Reinforcement Learning)
یادگیری تقویتی، رویکردی متفاوت نسبت به دو الگوی قبلی است که در آن یک عامل (Agent) در محیط عملیاتی قرار میگیرد و با انجام اقدامات مختلف، پاداش یا جریمه دریافت میکند. در این رویکرد، هدف عامل یادگیری استراتژی بهینه برای به حداکثر رساندن مجموع پاداشها در طول زمان است. به طور خلاصه، این فرایند را میتوان یادگیری از طریق آزمون و خطا و با تکیه بر بازخوردهای محیط دانست.
انواع الگوریتمهای یادگیری ماشین
در این بخش به بررسی برخی از مهمترین الگوریتمهای یادگیری ماشین میپردازیم و مفاهیم پایه، نحوه عملکرد، مزایا، معایب و کاربردهای عملی هر یک را بررسی میکنیم.
رگرسیون خطی (Linear Regression)
رگرسیون خطی، سنگ بنای بسیاری از تحلیلهای آماری و مدلهای یادگیری ماشین است. این الگوریتم، بر اساس فرض وجود یک رابطه خطی بین متغیرهای مستقل (ویژگیها) و متغیر وابسته (هدف) استوار است و سعی میکند با تکیه بر دادهها، بهترین خط ممکن را ترسیم کند. این خط به گونهای ترسیم میشود که مجموع مربعات خطا (Sum of Squared Errors – SSE) را به حداقل برساند و پیشبینی را تا حد امکان به واقعیت نزدیک کند.
بیشتر بخوانید: پیشنیازهای سختافزاری برای هوش مصنوعی و یادگیری ماشین
رگرسیون خطی نیازمند دادههایی با رابطه تقریباً خطی است. در صورتی که بین دادهها رابطه غیرخطی برقرار باشد، اطمینان به نتایج دریافتی هم کاهش پیدا میکند. علاوهبراین، رگرسیون خطی به دادههای نرمال شده بسیار حساس است. از همین رو، پیشپردازش دادهها (مانند دستهبندی و مقیاسبندی) در این الگوریتم از اهمیت ویژهای برخوردار است. به دلیل سادگی و تفسیرپذیری بالا، رگرسیون خطی همچنان یک انتخاب مناسب برای بسیاری از مسائل است، به خصوص در زمانی که سرعت و سادگی مهمتر از دقت حداکثری است.
برای محاسبه رگرسیون خطی از معادله زیر استفاده میشود:
Y= a *X + b
در این معادله:
Y متغیر وابسته
a شیب
X متغیر مستقل
b عرض از مبدأ
- مزایا: پیادهسازی و تفسیر آسان، نیاز به منابع محاسباتی کم
- معایب: فرض خطی بودن رابطه بین متغیرها، حساسیت به دادههای پرت (Outliers)
- کاربردها: پیشبینی قیمت مسکن، تخمین فروش، تحلیل روند بازار سهام، پیشبینی دما

رگرسیون لجستیک (Logistic Regression)
هرچند رگرسیون لجستیک نام رگرسیون را یدک میکشد، اما بیش از آن یک الگوریتم طبقهبندی (Classification) است. این الگوریتم برای پیشبینی احتمال عضویت یک نمونه در یک دسته خاص استفاده میشود. به همین منظور، رگرسیون لجستیک یک تابع سیگموئید (Sigmoid) را بر رابطه خطی بین متغیرهای مستقل (ویژگیها) و متغیر وابسته (دسته) اعمال میکند.
تابع سیگموئید، خروجی را به یک مقدار بین ۰ و ۱ محدود میکند که این مقدار، بهعنوان احتمال تعلق داشتن به یک دسته (مثلاً “بله” یا “خیر”) تفسیر میشود. سپس یک آستانه (Threshold) تعیین میشود (معمولاً ۰.۵) و نمونههایی که احتمال پیشبینی شده آنها بالاتر از این آستانه باشد، به یک دسته و نمونههایی که احتمال پیشبینی شده آنها پایینتر از این آستانه باشد، به دسته دیگر انتقال پیدا میکنند.
به بیان دیگر، رگرسیون لجستیک به دنبال یافتن بهترین ضرایب برای متغیرهای مستقل است که بتواند این رابطه خطی را به بهترین شکل به تابع سیگموئید تبدیل کند و از این طریق، به دقیقترین پیشبینی ممکن برسد. این الگوریتم با استفاده از دادههای آموزشی، ضرایب را به گونهای که تابع هزینه (Loss Function) را به حداقل برساند. این تابع، نمایانگر اختلاف بین مقادیر پیشبینی شده و مقادیر واقعی است.
- مزایا: سادگی، سرعت پیادهسازی بالا و اثبات ریاضیاتی قوی
- معایب: فرض خطی بودن رابطه بین متغیرها، حساسیت به دادههای پرت (Outliers)، عدم توانایی در مدلسازی روابط پیچیده، مشکل در مدیریت دادههای نامتوازن (Imbalanced Datasets)
- کاربردها: پیشبینی احتمال خرید محصول، ارزیابی ریسک اعتباری، تشخیص بیماری، تشخیص محتوای اسپم
ماشین بردار پشتیبان (SVM – Support Vector Machine)
ماشین بردار پشتیبان (SVM) بهعنوان یکی از الگوریتمهای قدرتمند و پرکاربرد در یادگیری ماشین شناخته میشود. هدف اصلی SVM، ترسیم برداری است که بهترین مرز را بین دستههای مختلف ایجاد کند. آنچه SVM را متمایز میکند، تمرکز آن بر به حداکثر رساندن حاشیه (Margin) است. به عبارت سادهتر،SVM تلاش میکند تا جداسازی دادهها را به گونهای انجام دهد که این فاصله تا حد امکان بزرگ باشد، زیرا این امر منجر به دقت و تعمیمپذیری بالاتر مدل میشود.
برای درک بهتر، فرض کنید چند تصویر سگ و گربه در دست داریم و میخواهیم آنها را از یکدیگر جدا کنیم. ماشین بردار پشتیبان یک خط (در حالت دوبعدی) یا یک صفحه (در حالت سهبعدی یا بیشتر) پیدا میکند که جداکننده سگها و گربهها از یکدیگر باشد. این خط یا صفحه به گونهای انتخاب میشود که نزدیکترین گربه و نزدیکترین سگ تا حد امکان از آن دور باشند. دادههای نزدیک به خط یا صفحه که در تعیین این خط یا صفحه نقش کلیدی دارند، «بردار پشتیبان» (Support Vectors) نامیده میشوند.
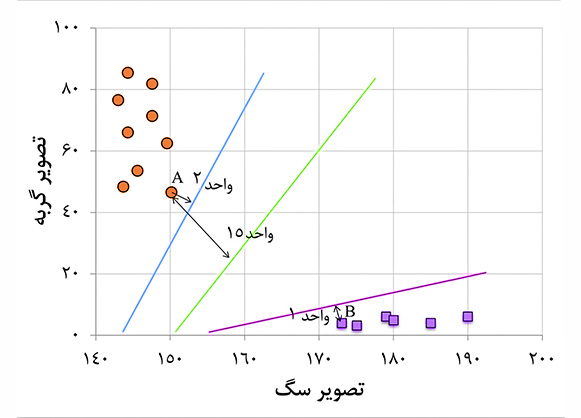
- مزایا: عملکرد خوب در مسائل طبقهبندی، استفاده از توابع هسته برای غیرخطیسازی
- معایب: پیچیدگی محاسباتی بالا، نیاز به تنظیم دقیق پارامترها، تفسیرپذیری دشوار
- کاربردها: تشخیص چهره، طبقهبندی تصویر، تشخیص تقلب، طبقهبندی متن
درخت تصمیم (Decision Tree)
در دنیای یادگیری ماشین، از «درخت تصمیم» بهعنوان یک الگوریتم بصری و قابل فهم نام برده میشود. این الگوریتم با ایجاد یک ساختار درختی، دادهها را بر اساس مجموعهای از قوانین طبقهبندی یا رگرسیون میکند. هر گره در درخت، نشاندهنده یک ویژگی و هر شاخه، نشاندهنده یک مقدار برای آن ویژگی است. درخت تصمیم با پرسیدن سؤالات متوالی در مورد ویژگیها، دادهها را به گرههای پایانی (برگها) تقسیم میکند که هر کدام نشاندهنده یک پیشبینی هستند.
یکی از نقاط قوت درخت تصمیم، قابلیت تفسیرپذیری بالای آن است. با بررسی ساختار درخت، میتوان به راحتی درک کرد که چگونه یک تصمیم خاص گرفته شده است. با این حال، درخت تصمیم به دلیل تمایل به بیشبرازش (Overfitting)، ممکن است در برخی موارد عملکرد ضعیفی داشته باشد. برای جلوگیری از بیشبرازش، معمولاً از تکنیکهای هرس (Pruning) و تنظیم عمق درخت استفاده میشود. جنگل تصادفی (Random Forest) بهعنوان ترکیبی از چندین درخت تصمیم، این مشکل را تا حد زیادی برطرف میکند.
- مزایا: تفسیرپذیری بالا، عدم نیاز به پیشپردازش دادهها
- معایب: احتمال بیشبرازش (Overfitting)، حساسیت به دادههای آموزشی
- کاربردها: طبقهبندی مشتری، ارزیابی ریسک، تشخیص بیماری، پیشبینی مسیر خرید مشتری
K-Means
K-Means یک الگوریتم خوشهبندی (Clustering) ساده و کارآمد است که برای تقسیم دادهها به گروه مجزا استفاده میشود. در این الگوریتم،K نمایانگر تعداد خوشهها است. این الگوریتم با هدف کاهش فاصله بین دادهها و مرکز خوشه مربوطه عمل میکند. در هر تکرار، الگوریتم ابتدا مراکز خوشهها را تعیین میکند و سپس دادهها را به نزدیکترین خوشه تخصیص میدهد. پس از آن، مراکز خوشهها بر اساس میانگین دادههای موجود در هر خوشه بهروزرسانی میشوند. این فرایند تا زمانی که مراکز خوشهها ثابت شوند، تکرار میشود.
یکی از چالشهای اصلی در استفاده از الگوریتم K-Means، تعیین مقدار K است. روشهای مختلفی برای تعیین K وجود دارد که از جمله آنها میتوان به روش Elbow و روش Silhouette اشاره کرد. علاوهبراین، باید توجه داشت که الگوریتم K-Means به مقدار اولیه مراکز خوشهها حساس است و ممکن است نتایج متفاوتی بر اساس مقدار اولیه مختلف به دست بیاید. با وجود این محدودیتها، K-Means به دلیل سادگی و سرعت بالا، همچنان یک انتخاب مناسب برای بسیاری از مسائل خوشهبندی است.
- مزایا: پیادهسازی آسان، مقیاسپذیری بالا
- معایب: نیاز به تعیین تعداد خوشهها (K)، حساسیت به مقدار اولیه مراکز خوشهها
- کاربردها: بخشبندی مشتری، تحلیل بازار، تشخیص ناهنجاری، خوشهبندی اسناد
PCA (Principal Component Analysis)
PCA (تجزیه کارایی اصلی) یک تکنیک کاهش ابعاد است که برای تبدیل دادهها به مجموعهای از ویژگیهای جدید (مؤلفههای اصلی) مورد استفاده قرار میگیرد. این ویژگیهای جدید براساس واریانس آنها مرتب میشوند؛ به گونهای که مؤلفههای اصلی با واریانس بالاتر، اطلاعات بیشتری را هم در بر میگیرند. هدف اصلی PCA، کاهش ابعاد دادهها در عین حفظ اطلاعات مهم و کلیدی است.
PCA در میان تکنیکهای غیرنظارتی دستهبندی میشود و همین باعث شده تا به گزینهای مناسب برای تجزیهوتحلیل دادههای بدون برچسب تبدیل شود. با این حال، باید توجه داشت که PCA، تفسیرپذیری دادهها را کاهش میدهد؛ چرا که ویژگیهای اصلی، ترکیبی از چندین ویژگی دیگر هستند و همین نکته ممکن است درک معنای آن را دشوار کند.
- مزایا: کاهش پیچیدگی محاسباتی، حذف نویز، بهبود عملکرد مدلهای یادگیری ماشین
- معایب: تفسیرپذیری دشوار، از دست دادن برخی از اطلاعات
- کاربردها: پردازش تصویر، تحلیل ژنتیک، تحلیل دادههای مالی
شبکه عصبی مصنوعی (Artificial Neural Network)
اگر بخواهیم چند مورد از قدرتمندترین الگوریتمهای یادگیری ماشین را نام ببریم، شبکه عصبی مصنوعی (ANNs) قطعاً یکی از نخستین انتخابها است. این شبکه که از ساختار مغز انسان الهام گرفته، از گرهها (Neurons) مختلف تشکیل شده است که در لایههای گوناگون به هم متصل شدهاند. هر گره ورودیها را دریافت، وزندهی و یک تابع فعالسازی را بر روی آنها اعمال میکند. خروجی هر گره، بهعنوان ورودی به گرههای لایه بعدی ارسال میشود.
بیشتر بخوانید: شبکه عصبی چیست و چه کاربردی دارد؟
شبکههای عصبی مصنوعی، به دلیل قابلیت یادگیری الگوهای پیچیده و عملکرد بالا در مسائل مختلف، امروزه از محبوبیت بالایی برخوردارند. با این حال، آموزش شبکههای عصبی مصنوعی نیازمند دادههای آموزشی زیاد و منابع محاسباتی قدرتمند است.
- مزایا: قابلیت یادگیری الگوهای پیچیده، عملکرد بالا در مسائل مختلف
- معایب: پیچیدگی محاسباتی بالا، نیاز به دادههای آموزشی زیاد، تفسیرپذیری دشوار
- کاربردها: پردازش تصویر، پردازش زبان طبیعی، ترجمه ماشینی، تشخیص چهره
یادگیری عمیق (Deep Learning)
یادگیری عمیق (Deep Learning)یکی از زیرمجموعههای شبکه عصبی مصنوعی به حساب میآید که از شبکههای بسیار عمیق با لایههای متعدد استفاده میکند. همین عمق بالا است که به شبکهها این امکان را میدهد تا ویژگیهای پیچیدهتری را از دادهها یاد بگیرند. شبکههای یادگیری عمیق در مسائل مختلفی مانند پردازش تصویر، پردازش زبان طبیعی و ترجمه ماشینی توانستهاند به نتایج شگفتانگیزی دست پیدا کنند.
با این حال، یادگیری عمیق نیازمند دادههای آموزشی بسیار زیاد و منابع محاسباتی فوقالعاده قوی است. بهعلاوه، شبکههای یادگیری عمیق به دلیل ساختار پیچیده و تعداد پارامترهای پرشمار، تفسیرپذیری بسیار دشواری دارند. همین موضوع باعث شده تا بسیاری از کارشناسان از یادگیری عمیق بهعنوان یک “جعبه سیاه” یاد کنند.
- مزایا: عملکرد بسیار بالا در مسائل پیچیده، قابلیت یادگیری ویژگیهای خودکار
- معایب: نیاز به دادههای آموزشی زیاد، نیاز به منابع محاسباتی قوی، تفسیرپذیری بسیار دشوار
- کاربردها: خودروهای خودران، تشخیص چهره، ترجمه ماشینی، تولید محتوا، چتباتهای هوشمند
الگوریتم نزدیکترین همسایه (KNN)
الگوریتم نزدیکترین همسایه یا به اختصار KNN، یک الگوریتم ساده و غیرپارامتری است که برای طبقهبندی و رگرسیون استفاده میشود. این الگوریتم با یافتن نزدیکترین نمونه در دادههای آموزشی (K) به یک نمونه جدید، پیشبینی را بر اساس رأی اکثریت (در طبقهبندی) یا میانگین (در رگرسیون) این همسایهها انجام میدهد. هرچند کهKNN یک الگوریتم ساده و قابل فهم است، اما ممکن است در دادههای با ابعاد بالا عملکرد ضعیفی داشته باشد. همچنینKNN به دادههای نرمال شده حساسیت زیادی دارد و از همین رو، پیشپردازش دادهها اغلب ضروری است.
- مزایا: پیادهسازی آسان، عدم نیاز به آموزش مدل
- معایب: نیاز به ذخیره کل دادههای آموزشی، حساسیت به انتخاب K، کندی در زمان پیشبینی
- کاربردها: سیستمهای توصیهگر، تشخیص تقلب، طبقهبندی تصویر
جنگل تصادفی (Random Forest)
جنگل تصادفی (Random Forest) یک الگوریتم قدرتمند و انعطافپذیر است که از ترکیب چندین درخت تصمیم تشکیل شده است. این الگوریتم با آموزش تعداد زیادی درخت تصمیم بر روی زیرمجموعههای تصادفی از دادهها و ویژگیها، یک مدل قوی و پایدار ایجاد میکند. هر درخت تصمیم در جنگل تصادفی بر روی یک زیرمجموعه تصادفی از دادهها و یک زیرمجموعه تصادفی از ویژگیها آموزش داده میشود که این امر، واریانس و بیشبرازش را به طور چشمگیری کاهش میدهد.
- مزایا: دقت بالا، مقاومت در برابر بیشبرازش، کاربری آسان، تشخیص دادههای پرت
- معایب: عدم شفافیت، زمان آموزش بالا، نیاز به حجم بالای حافظه
- کاربردها: طبقهبندی تصاویر، تشخیص تقلب، پیشبینی فروش، تحلیل ریسک اعتباری، پیشبینی قیمت سهام
نگاهی به کاربردهای یادگیری ماشین در دنیای واقعی
طی سالهای اخیر، الگوریتمهای یادگیری ماشین از چارچوب آزمایشگاهها و مراکز تحقیقاتی خارج شدهاند و بهطور گستردهای در حوزههای گوناگون مورد استفاده قرار میگیرند. در ادامه، به برخی از کاربردهای یادگیری ماشین در دنیای واقعی نگاهی میاندازیم.
· بازاریابی و سفارشیسازی تبلیغات
یکی از حوزههایی که طی سالهای اخیر با آغوشی باز به استقبال فناوری یادگیری ماشین رفته، شاخه بازاریابی و تبلیغات است. امروزه از الگوریتمهای یادگیری ماشین مانند رگرسیون لجستیک، درختهای تصمیم و شبکههای عصبی به منظور پیشبینی رفتار مشتریان (از جمله احتمال خرید، ترک سرویس یا پاسخگویی به تبلیغات) استفاده میشود.
از آنجایی که وبسایتها و اپلیکیشنها به دادههای زیادی از مشتریان از جمله سابقه خرید، بازدید از وبسایت، کلیک روی تبلیغات و اطلاعات جمعیتشناختی دسترسی دارند، میتوانند مدلهای یادگیری ماشین را با دقت بالایی آموزش دهند. علاوه بر این، یادگیری ماشین در سفارشیسازی تبلیغات هم نقش مهمی ایفا میکند و با پیشنهاد تبلیغات مرتبط به مشتریان بر اساس علایق و نیازهایشان، میزان اثرگذاری تبلیغات و رضایتمندی مشتریان را به طور فزایندهای افزایش میدهد.
· پزشکی و سلامت
با ورود الگوریتمهای یادگیری ماشین به دنیای پزشکی، بسیاری از متخصصان این فناوری را تحولی در زمینه تشخیص، درمان و پیشگیری از بیماریها دانستند. الگوریتمهای طبقهبندی مانند ماشینهای بردار پشتیبان (SVM) و شبکههای عصبی عمیق (CNN)، گزینههایی ایدهآل برای تشخیص بیماریهایی مانند سرطان، دیابت و بیماریهای قلبی از روی دادههای بالینی به حساب میآیند. شبکههای عصبی عمیق بهویژه در تجزیهوتحلیل تصاویر پزشکی مانند MRI و CT اسکن بسیار مؤثر هستند؛ چرا که میتوانند الگوهای ظریفی را در تصاویر شناسایی کنند که ممکن است توسط چشم انسان قابل تشخیص نباشند. علاوهبراین، نباید نقش یادگیری ماشین در پیشبینی خطر ابتلا به بیماریها بر اساس عوامل خطر فردی، مانند سابقه خانوادگی، سبک زندگی و دادههای ژنتیکی را نادیده گرفت.
· مالی و بانکی
در صنایع مالی و بانکی، الگوریتمهای یادگیری ماشین به ابزاری ارزشمند برای مقابله با تقلب، ارزیابی ریسک اعتباری و اتوماسیون فرایندهای معاملاتی تبدیل شدهاند. امروزه بانکها و مؤسسات مالی متعددی در سراسر دنیا از الگوریتمهای تشخیص ناهنجاری (Anomaly Detection) و طبقهبندی مانند درختهای تصمیم و جنگلهای تصادفی (Random Forest) برای شناسایی تراکنشهای مشکوک و جلوگیری از تقلب در حسابهای بانکی و معاملات آنلاین استفاده میکنند.
· خودروهای خودران
خودروهای خودران برای اینکه بتوانند در محیطهای شهری و غیرشهری به رانندگی بپردازند، بهشدت به الگوریتمهای یادگیری ماشین وابستهاند. شبکههای عصبی کانولوشنال (CNN) برای تجزیهوتحلیل تصاویر و ویدئوهای گرفته شده از دوربینها و رادارها استفاده میشوند تا محیط اطراف خودرو را درک کنند و مواردی مانند خودروها، عابران پیاده، علائم راهنمایی، خطوط جاده و اشیائی از این دست را تشخیص دهند. این الگوریتمها، خودرو را به گونهای آموزش میدهند که با انجام اقدامات خاص در شرایط مختلف پاداش دریافت کند و در نهایت یاد بگیرد که چگونه بهترین تصمیمات را برای رسیدن به هدف خود اتخاذ کنند.
· پردازش زبان طبیعی (NLP)
پردازش زبان طبیعی (NLP) یکی حوزههای یادگیری ماشین است که بر روی تعامل کامپیوترها و زبان انسانی تمرکز دارد. مدلهای زبانی بزرگ (Large Language Models) مانند BERT و GPTتماماً بر پایه شبکههای عصبی ترانسفورمر (Transformer Networks) توسعه پیدا کردهاند و توانستهاند در وظایفی مانند ترجمه ماشینی، تحلیل احساسات و پاسخگویی به سؤالات، عملکرد درخشانی را از خود به نمایش بگذارند.
· امنیت سایبری
در حوزه امنیت سایبری، از الگوریتمهای یادگیری ماشین بهعنوان ابزاری حیاتی برای تشخیص و پیشگیری از حملات به سیستمها و شبکهها استفاده میشود. الگوریتمهای تشخیص نفوذ (Intrusion Detection) با استفاده از دادههای ترافیک شبکه و لاگهای سیستم، الگوهای مشکوکی را شناسایی میکنند که ممکن است نشاندهنده یک حمله باشند. بهعلاوه، الگوریتمهای طبقهبندی مانند ماشینهای بردار پشتیبان (SVM) و جنگلهای تصادفی (Random Forest) اغلب برای شناسایی بدافزارها بر اساس ویژگیهای کد باینری و رفتار آنها در سیستم مورد استفاده قرار میگیرند.
کاربرد الگوریتمهای یادگیری ماشین، تنها منحصر به موارد بالا نیست و میتوان ردپای این فناوری را در حوزههای متنوعی مانند بهینهسازی زنجیره تأمین، دستیارهای مجازی، چتباتهای هوشمند، تحلیل و خلاصهسازی محتوا، موتورهای جستجو و موارد بیشمار دیگر، به وضوح مشاهده کرد.
جمعبندی
الگوریتمهای یادگیری ماشین، امروزه به عضوی جداییناپذیر از کسبوکارها و زندگی روزمره مردم تبدیل شدهاند. تنوع این الگوریتمها باعث شده تا برای هر نیازی، چندین راهکار مختلف وجود داشته باشد و توسعهدهندگان بتوانند متناسب با پروژه خود، یک یا چند مورد از این الگوریتمها را به کار بگیرند. برخی از این الگوریتمها مانند لجستیک خطی و درخت تصمیم، گزینههایی سبک و در عین حال کاربردی به حساب میآیند که برای اجرا به منابع محاسباتی کمی نیاز دارند. در مقابل، الگوریتمهای شبکه عصبی مصنوعی و یادگیری عمیق، عملکرد فوقالعادهای در حل مسائل پیچیده دارند و به همان میزان به زیرساختهای محاسباتی قدرتمند وابستهاند. پیشنهاد میشود که پیش از استفاده از هر یک از الگوریتمهای یادگیری ماشین در پروژههای خود، با زوایای مختلف آن بهخوبی آشنا شوید و با آگاهی کامل به پیادهسازی آن بپردازید.








