
آیا ماشینها میتوانند دنیای اطراف را آنگونه که ما درک میکنیم، بفهمند؟ شاید این سؤال در ابتدا کمی عجیب به نظر برسد؛ پاسخ در یک روش یادگیری نهفته است که به ماشینها کمک میکند تا با مشاهده و تکرار، تجربه کسب کنند. درست مانند یک آشپز حرفهای که در اوایل کار، غذاها را از روی دستورات آشپزی تهیه میکند و پس از مدتی، خود به یک آشپز حرفهای تبدیل میشود. این روش در دنیای ماشینها تحت یک عنوان شناخته میشود: یادگیری با نظارت.
در این مطلب، نگاهی عمیق به روش یادگیری با نظارت میاندازیم و مزایا، معایب، الگوریتمها و کاربردهای آن را بهطور مفصل بررسی میکنیم. با ما همراه باشید.
یادگیری با نظارت چیست؟
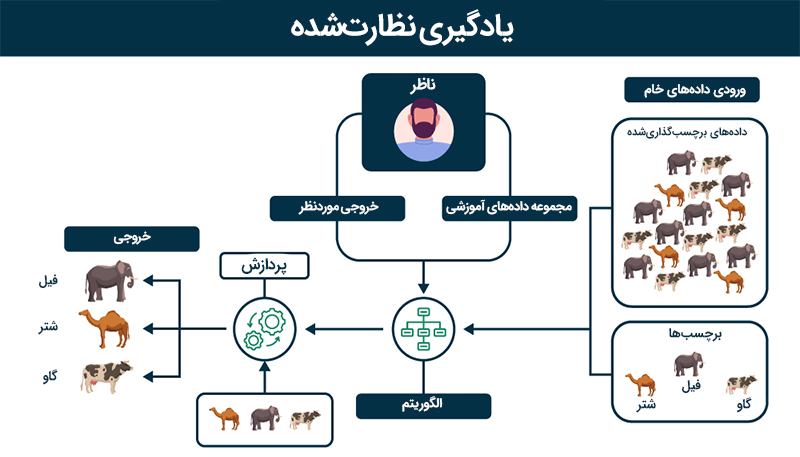
یادگیری با نظارت (Supervised Learning)، یکی از روشهای کلیدی در حوزه یادگیری ماشین (Machine Learning) است که در آن از دادههای برچسبگذاری شده برای آموزش الگوریتمهای هوش مصنوعی استفاده میشود. این الگوریتمها وظیفه دارند که الگوهای اساسی را بشناسند و روابط بین ویژگیهای ورودی و خروجی را شناسایی کنند. در این روش، هر نمونه داده شامل مجموعهای از ویژگیهاست که بهعنوان ورودی (Input) شناخته میشود. برچسبها یا نتایج مرتبط با این ویژگیها نیز تحت عنوان خروجی (output) در نظر گرفته میشوند. به بیان ساده:
«در روش یادگیری با نظارت، دادهها شامل مثالهایی هستند که به مدل یاد میدهند برای هر ورودی، چه خروجی مناسب است.»
بیشتر بخوانید: یادگیری بدون نظارت چیست؟
برای مثال، یک سیستم یادگیری با نظارت که برای تشخیص دستخط طراحی شده است را بررسی میکنیم. در این روش، تصاویر حاوی اعداد تحت عنوان ورودی در اختیار مدل قرار میگیرد و برچسب عدد مرتبط به هر تصویر بهعنوان خروجی مشخص میشود.
حال این وظیفه مدل است که با بررسی نمونههای دریافتشده، یاد بگیرد که چگونه ویژگیهای بصری مانند اندازه و شکل خطوط را به اعداد مشخص ربط بدهد. پس از این، هر وقت که تصویری جدید به مدل داده شود، مدل میتواند پیشبینی کند که عدد موجود در تصویر چیست.
مزایا و معایب یادگیری با نظارت چیست؟
یادگیری تحت نظارت هم مانند بسیاری از روشهای دیگر، دارای معایب و مزایای گوناگونی است. از همین جهت، به توسعهدهندگان توصیه میشود قبل از بهکارگیری سیستم یادگیری با ناظر، به تمامی جوانب مثبت و منفی این روش تسلط پیدا کنند. در ادامه، برخی از مزایا و معایب یادگیری با نظارت را بررسی میکنیم.
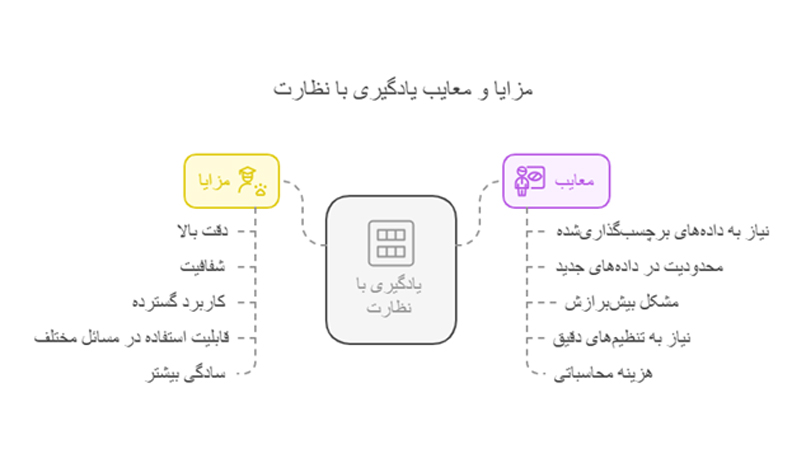
مزایای یادگیری با نظارت
- دقت بالا: از آنجا که در روش یادگیری ماشین با نظارت از دادههای برچسبگذاریشده استفاده میشود، پیشبینیهای انجامشده نیز معمولا از دقت بالایی برخوردارند. البته دستیابی به چنین دقتی نیازمند یک شرط مهم است؛ تمامی دادههایی که در اختیار مدل قرار میگیرد، میبایست از کیفیت بالایی برخوردار باشند و دادههایی تمیزشده به مدل ارائه شود.
- شفافیت: فرایند آموزش و ارزیابی در مدل یادگیری با نظارت کاملا واضح و شفاف است. به همین جهت، میتوان عملکرد مدل را بهراحتی با استفاده از دادههای آزمایشی، ارزیابی کرد.
بیشتر بخوانید: پیش بینی و تحلیل رفتار مشتری
- کاربرد گسترده: یکی از مزایای مهمی که بسیاری از توسعهدهندگان را به استفاده از روش یادگیری ماشین با ناظر سوق میدهد، کاربرد گسترده این سیستم برای کاربردهای گسترده است. امروزه یادگیری از روی داده های برچسب دار به طور گسترده در حوزههایی مانند جمله دستهبندی تصاویر، شناسایی گفتار و پیشبینی مالی و… مورد استفاده قرار میگیرد.
- قابلیت استفاده در مسائل مختلف: یادگیری با نظارت، یکی از روشهای پرکاربرد در مسائل مختلف است. اگر نگاهی به مسئلههای دستهبندی (Classification) و رگرسیون (Regression) بیندازیم، میتوانیم رد پای روش یادگیری با ناظر را در این موارد به وضوح مشاهده کنیم.
- سادگی بیشتر نسبت به «یادگیری بدون نظارت»: پیادهسازی سیستم یادگیری ماشین با نظارت، معمولا نسبت به سایر روشها مانند یادگیری بدون ناظر، پیچیدگی کمتری دارد؛ چرا که در این روش، از دادههای برچسبگذاریشده استفاده میشود و توسعهدهندگان، کنترل بیشتری روی مدل دارند.
معایب یادگیری با نظارت
- نیاز به دادههای برچسبگذاریشده: یکی از اصلیترین چالشهای سیستم یادگیری با ناظر، نیاز به دادههای برچسبگذاریشده است. جمعآوری و برچسبگذاری دادهها، فرایندی زمانبر و هزینهبر است و در صورتی که این فرایند بهدرستی انجام نشود، شاهد عملکرد مناسبی در مدل نهایی نیستیم.
- محدودیت در دادههای جدید: مدل یادگیری از روی داده های برچسب دار در مواجه با دادههایی مشابه با دادههای آموزشی، عملکرد درخشانی دارد؛ اما این تیغ دولبه میتواند به ضرر این روش تمام شود. در صورتی که دادههایی نویزی، جدید و بیشباهت به دیتاهای آموزشی در اختیار سیستم یادگیری با نظارت قرار بگیرد، باید انتظار داشت که عملکرد مدل با کاهش قابل توجهی همراه باشد.
- مشکل Overfitting (بیشبرازش): این چالش زمانی رخ میدهد که یک مدل، تا حدی به دادههای آموزشی متکی میشود که نهتنها الگوهای واقعی را در دادهها تشخیص میدهد، بلکه نویزها یا جزئیات بیاهمیت را نیز به عنوان الگو تلقی میکند. این چالش زمانی پدید میآید که دادههای آموزشی کافی در دسترس نیست و مدل تمایل پیدا میکند جزئیات همان دادههای محدود را بیش از حد یاد بگیرد. در نتیجه، مدل نهایی نمیتواند آنطور که باید پاسخگوی دادههای جدید و آزمایشی باشد.
- نیاز به تنظیمهای دقیق: در یادگیری با نظارت، الگوریتمهای مختلف دارای پارامترهای قابل تنظیم (Hyperparameters) هستند که نقش مهمی در عملکرد و دقت مدل نهایی دارند. حال اگر این تنظیم بهدرستی انجام نشود، نتیجه آن را میتوان در کیفیت پایین پیشبینیهای نهایی و همچنین بالارفتن زمان مورد نیاز برای آموزش، مشاهده کرد.
- هزینه محاسباتی: در سیستم یادگیری از روی دادههای برچسبدار، محاسبات نقش کلیدی دارند و نیاز به زیرساختها و سختافزارهای گران قیمت، میتواند یکی از موانع پیش پای توسعهدهندگان باشد. هرچند این چالش در دادههای محدود آنچنان به چشم نمیآید؛ اما هنگامی که قصد پردازش حجم زیادی از کلاندادههای برچسبگذاری شده را داشته باشید، هزینه محاسباتی به طور قابل توجهی افزایش پیدا میکند.
در مجموع، یادگیری تحت نظارت، یکی از بهترین گزینهها برای مسائل مشخص و ساختاریافته به حساب میآید؛ اما برای دادههای پیچیده، جدید و ناشناخته، ممکن است با محدودیتهایی مواجه شود و نتواند انتظارات توسعهدهندگان را به طور کامل برآورده کند.
مقایسه یادگیری با نظارت (supervised) و بدون نظارت (unsupervised)
تا به اینجا، از یادگیری با ناظر گفتیم و به جنبههای مثبت و منفی آن پرداختیم. در کنار این روش، سیستم «یادگیری بدون نظارت» (Unsupervised) قرار دارد که به شیوهای متفاوت، دادهها را دریافت و به خروجی مورد نظر دست پیدا میکند. در ادامه، این دو مدل را با یکدیگر مقایسه میکنیم و به کاربردها، مزایا و معایب هرکدام میپردازیم.
بیشتر بخوانید: تشخیص حالت و آناتومی بدن به کمک بینایی ماشین
- یادگیری با نظارت
در این روش، مدل با استفاده از دادههای برچسبدار (Labeled Data) آموزش میبیند. در نتیجه، هر داده ورودی، خروجی مشخصی دارد و معمولا در پاسخ به سوالات از پیشآموزشدیده و تکراری، از دقت بالایی برخوردار است.
مثالهای کاربردی:
- تشخیص ایمیلهای اسپم
- تشخیص چهره در تصاویر
- پیشبینی قیمت مسکن بر اساس ویژگیهایی مانند متراژ، موقعیت و سال ساخت
- تحلیل اطلاعات مالی و تعیین میزان ریسک وام دادن به مشتریان
مزایا:
- نیازی به برچسبگذاری دادهها ندارد، بنابراین در زمان و هزینه صرفهجویی میشود.
- انعطافپذیری بالای سیستم یادگیری بدون ناظر، امکان کار بر روی دادههای متنوع را فراهم میکند.
- به کشف الگوهای پنهان و ناهنجاریهای ناشناخته کمک میکند.
معایب:
- دقت آن تضمین شده نیست؛ چرا که بر اساس دادههای برچسبگذاریشده آموزش ندیده است.
- از آنجا که این سیستم به کشف الگوهای ناشناخته میپردازد، میتواند تفسیر نتایج را به فرایندی دشوار و غیرقابل فهم تبدیل کند.
- برای پیدا کردن الگوهای دقیق، به حجم زیادی از دادهها وابسته است.
| ویژگی | یادگیری بانظارت | یادگیری بدون نظارت |
| نوع داده | برچسبدار | بدون برچسب |
| کاربر | پیشبینی و طبقهبندی | کشف الگو وخوشهبندی |
| نیاز به داده زیاد | بله | خیر |
| دقت مدل | معمولا بالا | منتغیر و گاهی پایینتر |
| هزینه آماده سازی داده | بالا(نیاز به برچسب گذاری) | کمتر |
| انعطاف پذیری | کمتر(به خروجیهای مشخص وابسته است) | بیشتر |
کدام روش مناسبتر است؟
اگر عامل دقت در پیشبینی برای شما در اولویت است، یادگیری تحت نظارت میتواند گزینه مناسبتری باشد. این روش در حوزههایی مانند پزشکی و تشخیص بیماری بر اساس علائم که دقیق بودن نتیجه اهمیت بسیار بالایی دارد، مورد استفاده قرار میگیرد. از طرفی، اگر زمان و هزینه شما محدود است و به حجم بالایی از دادهها دسترسی دارید، میتوانید فرایند کشف الگوهای جدید را به یادگیری بدون نظارت بسپارید.
دادههای برچسبگذاریشده چیست؟
هنگام مطالعه مطالب بالا، بارها به عبارت «دادههای برچسبگذاری شده» مواجه شدهاید. اما منظور از این عبارت چیست و چه کاربردهایی دارد؟
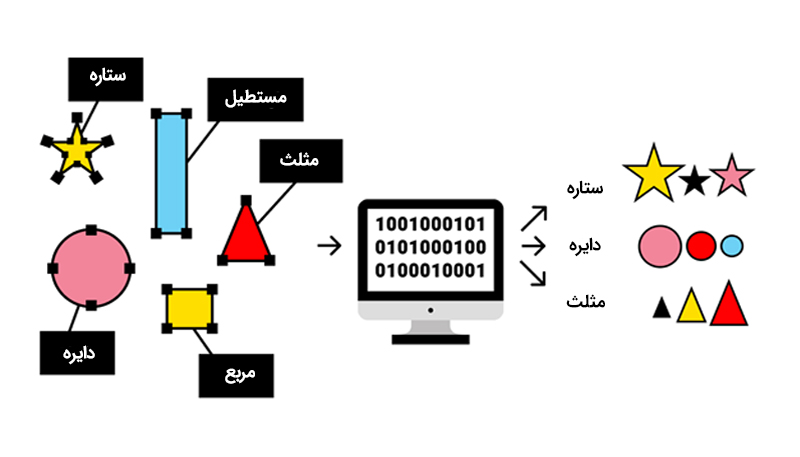
دادههای برچسبگذاریشده (Labeled Data) به مجموعهای از دادهها گفته میشود که برای هر نمونه، یک یا چند برچسب (Label) در نظر گرفته میشود. این برچسبها، هم توسط انسان و هم از طریق الگوریتمهای هوش مصنوعی به نمونهها اختصاص پیدا میکند و از این طریق، مشخص میشود که هر داده به چه گروه یا دستهای تعلق دارد.
دادههای برچسبگذاری شده، نقش مهم و اثرگذاری در سیستم یادگیری ماشین با نظارت ایفا میکند. به طور مثال، در یک سیستم تشخیص چهره که از روش دادههای برچسبگذاریشده استفاده میکند، تصاویر بهعنوان ورودی در نظر گرفته میشوند و برچسبهایی مانند “چهره” یا “غیرچهره” به آنها اختصاص پیدا میکند.
همچنین در پردازش زبان طبیعی (NLP)، دادههای برچسبگذاریشده کمک میکنند تا احساسات موجود در متون، موجودیتهای نامدار (مثل نام اشخاص و مکانها) و دیگر ویژگیهای زبانی، تشخیص داده شوند. علاوه بر این، بینایی کامپیوتر نیز یکی دیگر از فناوریهایی است که استفاده زیادی از دادههای برچسبگذاری شده دارد و این دادهها را در تشخیص اشیا و سیستمهای خودران مورد استفاده قرار میدهد.
روشهای مختلف برچسبگذاری دادهها کدامند؟
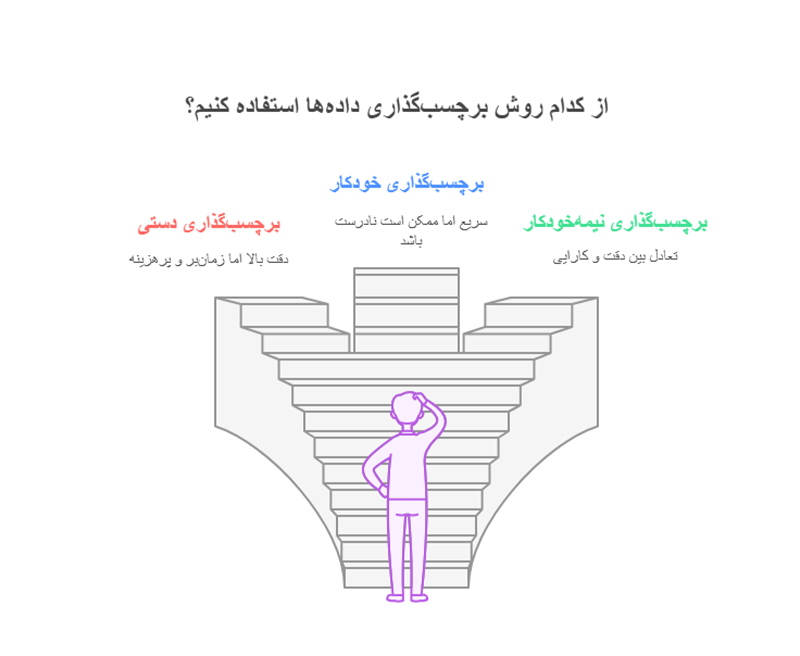
برچسبگذاری دادهها معمولا به سه روش انجام میشود:
1- روش دستی: در این روش، نمونهها توسط افراد متخصص و یا کاربران به صورت دستی برچسبگذاری میشوند.
2- روش خودکار: در روش خودکار، الگوریتمهای یادگیری ماشین، وظیفه برچسبگذاری دادهها را برعهده میگیرند و بدون دخالت انسان، تمام یا بخشی از دادهها را برچسبگذاری میکنند.
3- روش نیمهخودکار: این روش، ترکیبی از دو روش دستی و خودکار است که در آن، نمونهها توسط ماشین برچسبگذاری میشوند و فرایند نظارت، اصلاح و تایید به صورت دستی توسط انسان انجام میشود.
هر کدام از این روشها، نقاط ضعف و قوت مختص به خود را دارند. برای مثال، روش دستی، فرایندی پرهزینه و زمانبر است و همچنین مستعد خطای انسانی است. از طرفی، روش خودکار از دقت صددرصدی برخوردار نیست و میتواند با برچسبزنی غلط، عملکرد نهایی سیستم را تضعیف کند. در نتیجه، استفاده درست و محاسبهشده از هر یک از این روشها برای برچسبگذاری نمونهها از اهمیت بالایی برخوردار است و پیشنهاد میشود که متناسب با نوع فعالیت خود، هر یک از این روشها را انتخاب کنید.
الگوریتمها و مراحل یادگیری با نظارت
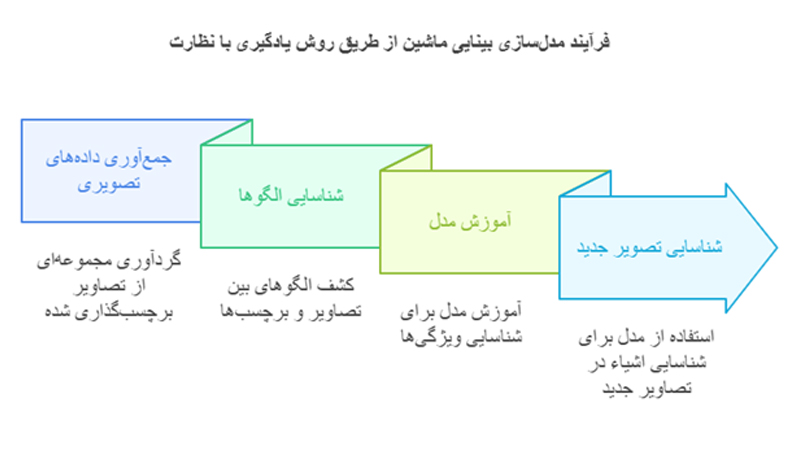
برای آنکه با روش یادگیری با نظارت به طور عمیق آشنا شویم، میبایست به الگوریتمها و مراحل یادگیری آن مسلط شویم. در ابتدا، مراحل یادگیری این روش جذاب را مرور میکنیم و سپس با کاربردیترین الگوریتمهای یادگیری با ناظر آشنا میشویم. روش یادگیری با نظارت از پنج مرحله کلی تشکیل میشود که هرکدام، نقش مهمی در ساخت و بهینهسازی مدل ایفا میکنند. این پنج مرحله به ترتیب زیر است:
1. گردآوری و آمادهسازی دادهها
اگر دادهها را مهمترین فاکتور در یادگیری ماشین قلمداد کنیم، بیراه نگفتهایم؛ چرا که کیفیت مدل نهایی، مستقیما با کیفیت دادههای ورودی در ارتباط است. هرچه مرحله گردآوری و آمادهسازی دادهها با دقت و کیفیت بیشتری انجام شود، زیربنای مدل نهایی مستحکمتر شده و دیگر مراحل با سهولت بیشتری تکمیل میشوند. به طور معمول، این مرحله از یک فرایند مشخص پیروی میکند که در ادامه، آن را بررسی میکنیم:
بیشتر بخوانید: هوشمصنوعی در پروژههای الکترونیکی
الف) جمعآوری دادهها
در این مرحله، دادههای موردنیاز برای آموزش مدل جمعآوری میشوند. این دادهها میتوانند از منابع مختلفی گردآوری شوند. منابعی مانند:
- پایگاههای داده عمومی همچون «Kaggle» و «UCI Machine Learning Repository»
- حسگرها و دستگاههای IoT
- دادههای حاصل از تعامل کاربران با سیستمها (مانند لاگهای وبسایت)
- دادههای تولیدشده توسط انسان (برچسبگذاری دستی روی تصاویر، متون و غیره)
ب) پاکسازی و پیشپردازش دادهها
دادههای خام، معمولا برای آموزش مدلهای حرفهای مورد استفاده قرار نمیگیرند؛ چرا که این دادهها دارای مشکلاتی مانند نویز، غلطهای نگارشی و ساختاری، فرمتهای ناسازگار، دادههای گمشده و… هستند که میبایست اصلاح شوند. برای پاکسازی دادهها، از روشهای گوناگونی استفاده میشود که موارد زیر، برخی از آنها هستند:
- حذف دادههای پرت (Outliers): حذف دادههایی که بهشدت با سایر نمونهها تفاوت دارند.
- مدیریت دادههای گمشده: پر کردن مقادیر از دسترفته با میانگین، میانه یا استفاده از تکنیکهای جایگزینی.
- حذف نویز: کاهش اطلاعات اضافی که نهتنها بر کیفیت مدل تاثیر مثبت نمیگذارد؛ بله با اثرگذاری منفی، عملکرد مدل را مختل میکند.
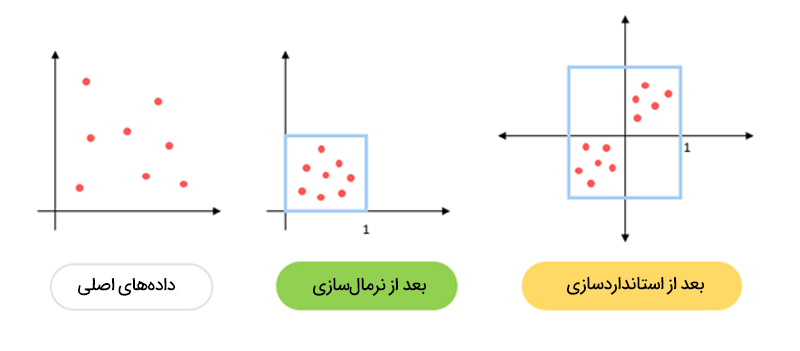
ج) استانداردسازی و نرمالسازی دادهها
- نرمالسازی (Normalization): تبدیل ویژگیها به بازهای مشخص (مثلاً [0,1]) برای افزایش کارایی مدل.
- استانداردسازی (Standardization): تبدیل دادهها به توزیعی با میانگین صفر و انحراف معیار یک.
- رمزگذاری ویژگیهای غیرعددی: تبدیل متغیرهای دستهای (مانند رنگها یا جنسیت) به دادههای عددی.
د) تقسیم دادهها به مجموعههای آموزشی و آزمایشی
برای ارزیابی مدلها، میبایست دادهها را به دو بخش کلی تقسیمبندی کنیم:
مجموعه آموزشی (Training Set): ۷۰٪ تا ۸۰٪ از دادهها برای آموزش مدل استفاده میشود.
مجموعه آزمایشی (Test Set): ۲۰٪ تا ۳۰٪ دادهها برای ارزیابی مدل در نظر گرفته میشود.
در برخی موارد، مجموعهای تحت عنوان دادههای اعتبارسنجی (Validation Set) هم در نظر گرفته میشود که برای تنظیم هایپر پارامترهای مورد استفاده قرار میگیرد.
2. انتخاب نوع مدل، مسئله و الگوریتم
پس از آمادهسازی دادهها، نوبت به انتخاب مدل مناسب میرسد. در این مرحله، مدلی انتخاب میشود که بتواند در تشخیص رابطه بین ویژگیها و خروجیها، بهترین عملکرد را از خود به نمایش بگذارد.
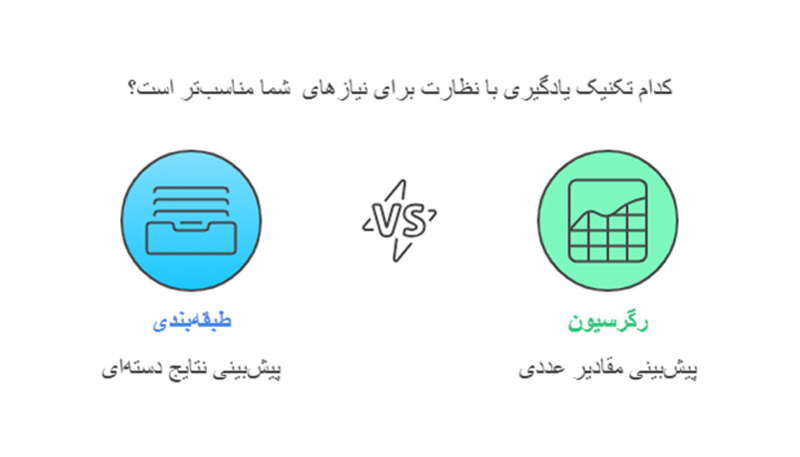
الف) انتخاب نوع مسئله
پیش از همه باید مشخص شود که مسئله طبقهبندی (Classification) است یا رگرسیون (Regression)
- طبقهبندی: پیشبینی خروجیهای دستهای (مانند تشخیص ایمیلهای اسپم یا غیر اسپم).
- رگرسیون: پیشبینی مقدار عددی (مانند پیشبینی قیمت سهام).
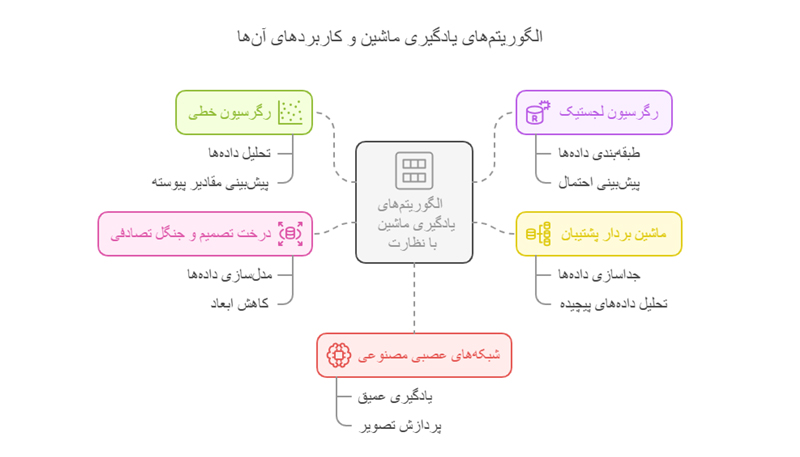
ب) انتخاب نوع الگوریتم
بسته به نوع دادهها و مسئله، الگوریتمهای مختلفی مورد استفاده قرار میگیرند:
- رگرسیون خطی (Linear Regression) برای مسائل رگرسیونی.
- رگرسیون لجستیک (Logistic Regression) برای طبقهبندی دودویی.
- ماشین بردار پشتیبان (SVM) برای دادههای پیچیدهتر.
- درخت تصمیم (Decision Tree) و جنگل تصادفی (Random Forest) برای دادههای متنوع و پیچیده.
شبکههای عصبی مصنوعی (Neural Networks) برای مسائل بزرگ و پردازش تصویر.
3. آموزش مدل
در این مرحله، مدل آماده است تا دادهها را دریافت کند و الگوی میان آنها را بیاموزد. به این منظور، مدل در ابتدا پارامترهای خود را بر اساس مجموعه آموزشی دریافت شده تنظیم میکند. در این مرحله، سه عمل اصلی وجود دارد که میتواند دقت مدل را به حد دلخواه برساند. این سه عمل شامل موارد زیر است:
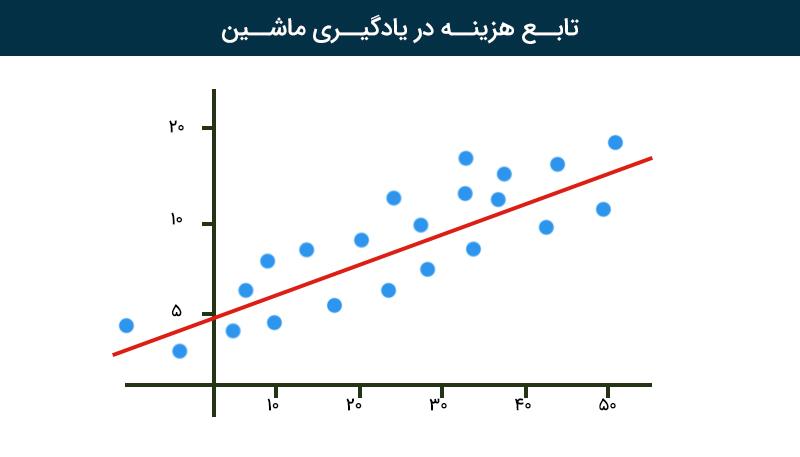
الف) انتخاب تابع هزینه (Loss Function)
تابع هزینه نشاندهنده میزان خطای مدل است و هدف یادگیری، به حداقل رساندن این خطا است. برخی از توابع هزینه رایج عبارتاند از:
- میانگین مربع خطا (MSE) برای مسائل رگرسیونی
- آنتروپی متقاطع (Cross-Entropy Loss) برای مسائل طبقهبندی
ب) بهینهسازی مدل
برای کاهش مقدار تابع هزینه، از الگوریتمهای بهینهسازی مانند گرادیان نزولی (Gradient Descent) استفاده میشود. این الگوریتمها، وظیفه بهروزرسانی وزنی مدل را بر عهده دارند.
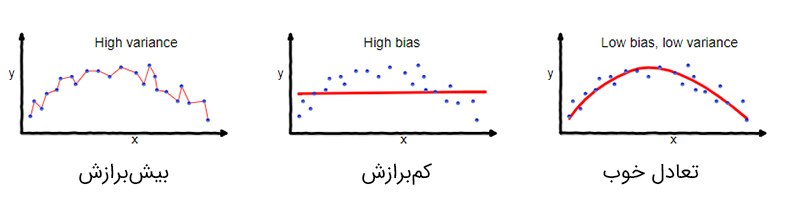
ج) جلوگیری از بیشبرازش (Overfitting)
مدل ممکن است بهشدت به دادههای آموزشی وابسته شود و عملکرد ضعیفی روی دادههای جدید داشته باشد. برای جلوگیری از این مشکل:
- از روش منظمسازی (Regularization) مانند L1 و L2 استفاده میشود.
- تکنیک دراپآوت (Dropout) در شبکههای عصبی برای کاهش پیچیدگی مدل بهکار میرود.
- استفاده از دادههای اعتبارسنجی برای تنظیم مدل مفید است.
4. ارزیابی و تنظیم مدل
حال که مدل بر پایه دادههای ورودی آموزش دیده، زمان بررسی و ارزیابی مدل فرا میرسد. در این مرحله، عملکرد مدل بر اساس سه معیار اصلی مورد آزمایش قرار میگیرد:
- دقت (Accuracy): نسبت پیشبینیهای صحیح به کل پیشبینیها.
- دقت و بازیابی (Precision & Recall): در مسائل عدمتوازن دادهها (مانند تشخیص سرطان) مهماند.
ضریب تعیین (R²) و میانگین مربع خطا(MSE) : برای مدلهای رگرسیونی.
5. پیادهسازی و استفاده از مدل
پس از اطمینان از عملکرد مطلوب مدل، میتوان آن را در محیط عملیاتی پیادهسازی کرد. مدل میتواند بهصورت یک API وب، نرمافزار موبایل یا سیستم پردازش بلادرنگ اجرا شود.
پس از این مراحل، کار مدل به انتها نمیرسد. یک مدل باکیفیت، بهطور مستمر بهروزرسانی میشود و با دریافت دادههای جدید، عملکرد خود را بهبود میبخشد. اگر قصد توسعه یک مدل یادگیری با نظارت را دارید، به هیچ عنوان بهروزرسانی مدل را نادیده نگیرید.
کاربردهای یادگیری با نظارت
اگر بخواهیم لیستی از کاربردیترین مدلهای یادگیری ماشین تهیه کنیم، روش یادگیری با نظارت، قطعا یکی از برترین گزینههاست. این روش در زمینههای گوناگونی مورد استفاده قرار میگیرد و دقت بالای آن، یادگیری با ناظر را به یکی از محبوبترین مدلها نزد توسعهدهندگان تبدیل کرده است. در ادامه، با برخی از این کاربردها آشنا میشویم و به دلایل این محبوبیت پی میبریم.
1- تشخیص تصویر و بینایی ماشین
امروزه ماشینها میتوانند محیط اطراف خود را ببینند، تصاویر را درک کنند و به تحلیل ویدئوها بپردازند. این قابلیت فوقالعاده به لطف یکی از زیرشاخههای هوش مصنوعی تحت عنوان بینایی ماشین (Computer Vision) به کامپیوترها اضافه شده است. یکی از روشهایی که نقش اساسی در توسعه مدلهای بینایی ماشین دارد، یادگیری با نظارت است.
برای آموزش مدلهای تشخیص تصویر، مجموعهای از تصاویر حاوی برچسب در اختیار مدل قرار میگیرد تا الگوی میان تصویر و برچسب، کشف شود. این برچسبها، هرکدام نشاندهنده یک مفهوم هستند. برای مثال، از طریق برچسبها مشخص میشود که یک تصویر شامل ماشین، درخت و چند گربه است. حال مدل، ویژگیهای هر یک از این مفاهیم را میآموزد و در آینده با دریافت یک تصویر جدید، میتواند وجود گربه را به درستی در آن تشخیص بدهد.
2– پردازش زبان طبیعی (NLP)
یکی دیگر از زیرشاخههای هوش مصنوعی که توانسته مرز میان انسانها و ماشینها را به حداقل برساند، فناوری پردازش زبان طبیعی (NLP) است. امروزه به لطف این فناوری، ماشینها میتوانند زبان انسانی را پردازش و درک کنند و حتی به شیوهای مشابه انسان، به آن پاسخ بدهند. پردازش زبان طبیعی برای انجام دقیق فعالیت خود نیازمند دادههای برچسبگذاری شده است؛ روشی که یادگیری با نظارت در آن بهترین عملکرد را دارد.
کاربردهای یادگیری با ناظر در پردازش زبان طبیعی، بسیار گسترده و متنوع است. از تحلیل احساسات و ترجمه هوشمند گرفته تا چتباتها و موتورهای جستجو، یادگیری با نظارت پتانسیل خود را به نمایش میگذارد و باعث شده تا NLP به یکی از کاربردیترین فناوریهای هوش مصنوعی تبدیل شود.
با پیشرفت یادگیری عمیق و شبکههای عصبی پیچیده، دقت و عملکرد مدلهای NLP به طور چشمگیری بهبود یافته است. مدلهایی مانند BERT و GPT توانستهاند مرزهای پردازش زبان را گسترش دهند و سیستمهایی ایجاد کنند که نهتنها قادرند متن را تحلیل کنند، بلکه امکان تولید پاسخهای منطقی و طبیعی را نیز دارند. این پیشرفتها نویددهنده آن است که آینده پردازش زبان طبیعی به سمت تعاملات هوشمندتر، سریعتر و کارآمدتر در حرکت است.
3– پیشبینی و تحلیل مالی
دقت و سرعت، دو فاکتور اصلی در دنیای مالی هستند که نقش بسزایی در موفقیت سرمایهگذاریها و مدیریت ریسک ایفا میکنند. به همین منظور، فعالان این حوزه از هر ابزاری که بتواند دقت و سرعت فعالیتهای اقتصادی را افزایش دهد، استقبال میکنند.
یکی از موثرترینِ این ابزارها، فناوری هوش مصنوعی است که طی سالهای اخیر، به کمک شرکتها و سرمایهگذاران آماده تا روندهای بازار را پیشبینی کرده و استراتژیهای مناسبی برای خرید، فروش یا نگهداری داراییها تدوین کنند. لازمه این کار، تحلیل دادههای مالی باکیفیت و برچسبگذاری شده است. کیفیت این دادهها از اهمیت فوقالعاده بالایی برخوردار است و حتی کوچکترین خطایی میتواند عملکرد مدل را با اختلال مواجه کند. به همین جهت، بهکارگیری روش یادگیری بدون ناظر در عرصه مالی چندان قابل اتکا نیست و در توسعه مدلهای حرفهای، معمولا از روش یادگیری با نظارت استفاده میشود.

تحلیل قیمت سهام، پیشبینی نوسانات بازار، شناسایی ریسکهای اقتصادی و تشخیص رفتارهای غیرعادی در معاملات، تنها بخشی از کاربردهای مدل یادگیری با نظارت در دنیای مالی است. این کاربردهای گسترده باعث شده تا مدلهای یادگیری با ماشین به یکی از کلیدیترین ابزارها در صنعت مالی تبدیل شوند و جایگاه خود را در موسسات مالی مشهور تثبیت کنند.
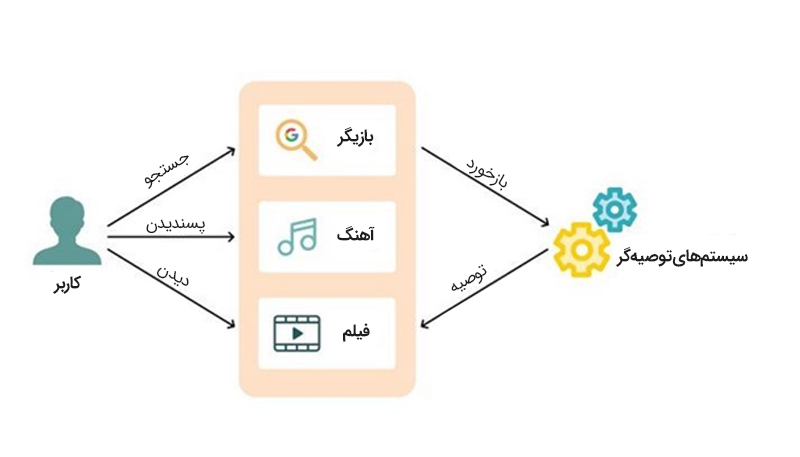
4– سیستمهای توصیهگر
اگر از کاربران پلتفرمهای استریم محتوا مانند Netflix و Spotify باشید و یا بخشی از زمان خود را در شبکههای اجتماعی میگذرانید، حتما متوجه این موضوع شدهاید که این سکوها پس از مدتی، سلیقه شما را میشناسند و محتوای مورد علاقهتان را به شما نمایش میدهند. این وظیفه سیستمهای توصیهگر (Recommender Systems) است که از مدلهای یادگیری ماشین استفاده کنند و با سلیقه کاربران همسو شوند.
در حال حاضر، این سیستمها نقش کلیدی در بهبود تجربه کاربری و افزایش تعامل مخاطبان با پلتفرمهای دیجیتال دارند؛ بهطوری که بسیاری از فروشگاههای اینترنتی توانستهاند با استفاده از این ابزار، فروش خود را تا چندین برابر افزایش دهند.
با پیشرفت یادگیری عمیق و افزایش حجم دادههای کاربران، دقت و کارایی سیستمهای توصیهگر به میزان قابلتوجهی بهبود یافته است. الگوریتمهایی مانند فیلتر مشارکتی، مدلهای مبتنی بر محتوا و شبکههای عصبی عمیق باعث شدهاند این سیستمها پیشنهادهایی دقیقتر و شخصیسازیشدهتر ارائه دهند.
دقت بالای مدل یادگیری از روی دادههای برچسب دار باعث شده تا کاربردهای این روش، تنها به موارد فوق خلاصه نشود. تشخیص بیماری و کاربردهای پزشکی، خودروهای خودران، تبلیغات هدفمند، بازاریابی دیجیتال و دهها کاربرد دیگر، یادگیری تحت نظارت را به یکی از نخستین انتخابهای توسعهدهندگان هوش مصنوعی تبدیل کرده است.
نتیجهگیری
یادگیری با نظارت یکی از روشهای کلیدی در حوزه یادگیری ماشین است که به دلیل دقت بالا، شفافیت و گستردگی کاربرد، جایگاه ویژهای در توسعه هوش مصنوعی دارد. این روش به کمک دادههای برچسبگذاریشده، مدلها را آموزش داده و به آنها امکان میدهد که الگوها و روابط میان دادهها را کشف کنند. هرچند این روش به دلیل نیاز به دادههای برچسبگذاریشده و هزینههای محاسباتی بالا، با چالشهایی روبهرو است؛ اما همچنان در مسائل مهمی همچون تشخیص تصویر، پردازش زبان طبیعی، تحلیل مالی و سیستمهای توصیهگر بسیار موفق عمل کرده است.
در نهایت، یادگیری با نظارت به دلیل پیشرفتهای اخیر در زمینه الگوریتمهای یادگیری عمیق، بهبود روشهای بهینهسازی و توسعه سختافزارهای محاسباتی، روزبهروز توانمندتر میشود. انتظار میرود با افزایش حجم دادهها و نیاز به سیستمهای هوشمندتر، این روش همچنان در آینده نقش پررنگی در توسعه فناوریهای نوین ایفا کند و مسیر پیشرفت هوش مصنوعی را هموارتر سازد.







![[تماشا کنید] آموزش فراخوانی سرویس ابری «احراز هویت فراشناسا»](https://api.ivira.ai/blog/wp-content/uploads/2024/05/sahabBlog-TS-853x479-1-300x168.jpg)
![[تماشا کنید] راهنمای افزودن سرویسهای ویرا به وبسایتها و اپلیکیشنها](https://api.ivira.ai/blog/wp-content/uploads/2025/03/19-300x168.jpg)


![[تماشا کنید] فراتر از پیکسلها؛ چگونه ماشینها جهان را میبینند و درک میکنند؟](https://api.ivira.ai/blog/wp-content/uploads/2025/03/07-1-300x168.jpg)

![[تماشا کنید] هر آنچه که در وبینار «هوش مصنوعی و تحول در پردازش صوت؛ فرصتها و دستاوردها» گذشت](https://api.ivira.ai/blog/wp-content/uploads/2025/03/18-300x168.jpg)
![[تماشا کنید] وبینار «فرصتهای هوش مصنوعی برای توسعه محصولات جدید» توسط ویرا برگزار شد](https://api.ivira.ai/blog/wp-content/uploads/2024/03/وبینار-ویرا-300x168.jpg)
