
مقدمه
احتمالا برای شما هم پیش آمده؛ دارید به موسیقی دلخواهتان در اسپاتیفای یا دیگر پلتفرمهای پخش موسیقی گوش میکنید که آن برنامه لیستی از آهنگهای مشابه را پیشنهاد میکند. آهنگهایی که دقیقا شبیه سلیقه موسیقایی شما هستند و با حال و هوای آهنگهای مورد علاقهتان همخوانی دارند. این تجربه تنها یک نمونه ساده اما کاربردی یادگیری ماشین بدون نظارت در زندگی روزمره ماست.
در پشت پرده این پیشنهادهای هوشمندانه و شنیدنی، چندین الگوریتم یادگیری بدون نظارت نهفته است که بدون دخالت مستقیم نیروی انسانی، الگوریتمهای پنهان در سلیقه موسیقایی کاربران را کشف میکند و بر اساس آن، پیشنهادهای شخصیسازی شده به آنها ارائه میدهد. در ادامه این متن همراه ما باشید تا با فرایند یادگیری نظارت نشده به عنوان یکی از روشهای مهم هوش مصنوعی بیشتر آشنا شوید.
یادگیری بدون نظارت چیست؟
یادگیری ماشین بی نظارت یک روش مهم در هوش مصنوعی و یادگیری ماشین است که در آن مدل با دادههای خام و البته بدون برچسب آموزش داده میشود. در این روش که کاملا برخلاف یادگیری با نظارت است؛ نیازی نیست که به دادهها برچسب بزنیم یا به سیستم بگوییم که دقیقا دنبال چه چیزی باید باشد. به عبارت دیگر، خود سیستم و کامپیوتر به طور خودکار، الگوها و ارتباطات موجود در دادهها را کشف میکند.
بگذارید این روش را با یک مثال ساده توضیح دهیم. فرض کنید یک جعبه پر از میوههای مختلف دارید، اما هیچ کدام از آنها برچسب ندارد. حالا اگر به یک فردی که هیچ شناختی از این میوهها ندارد و از ملیت دیگری است بگویید “خودت به میوهها نگاه کن و میوههای مشابه را جدا کن” آن فرد بدون اینکه بداند اسم این میوهها چیست، میتواند سیبها را کنار هم، موزها را کنار هم و پرتقالها را کنار هم بگذارد. یادگیری بدون نظارت دقیقا همین کار را میکند، خودش سعی میکند دادههای مشابه را پیدا و سپس دستهبندی کند.
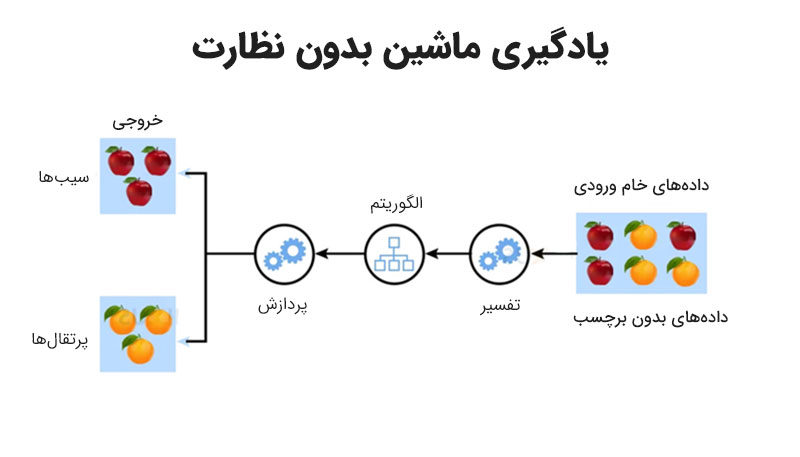
تفاوت یادگیری نظارتشده و یادگیری بدون نظارت
حالا همان مثال میوهها را در نظر داشته باشید تا تفاوت یادگیری با نظارت و یادگیری بدون ناظر را توضیح دهیم. تصور کنید میخواهیم به یک سیستم هوشمند یاد بدهیم که میوههای مختلف را از هم تشخیص دهد. در یادگیری با نظارت، به سیستم مجموعهای از تصاویر میوههای مختلف را میدهیم که هر کدام برچسب مشخصی دارند. “این یک سیب است”، “این یک پرتقال است.”، و غیره. سیستم میتواند با دیدن این مثالهای برچسبخورده یاد بگیرد که ویژگیهای هر میوه چیست تا خودش بتواند در آینده میوههای جدید را دستهبندی کند.
بیشتر بخوانید: یادگیری بانظارت چیست؟
اما در یادگیری نظارت نشده (unsupervised learning)، ما فقط تصاویر میوهها را به سیستم میدهیم، بدون هیچ برچسبی. سیستم خودش میتواند بر اساس شباهتها و تفاوتهای موجود در شکل، رنگ و سایر ویژگیها، خودش میوهها را گروهبندی کند. مثلا ممکن است تمام میوههای گرد و قرمز را در یک گروه و میوههای زرد و گرد را در گروه دیگری قرار دهد، بدون اینکه بداند هر گروه چه نامی دارد؛ پس این دو روش تفاوت بسیار مهمی در هدف و نحوه یادگیری دارند. اما به غیر از این؛ این دو روش چه تفاوتهای دیگری هم دارند؟ در ادامه همراه ما باشید تا تفاوت اصلی یادگیری بدون ناظر و یادگیری با ناظر بپردازیم.
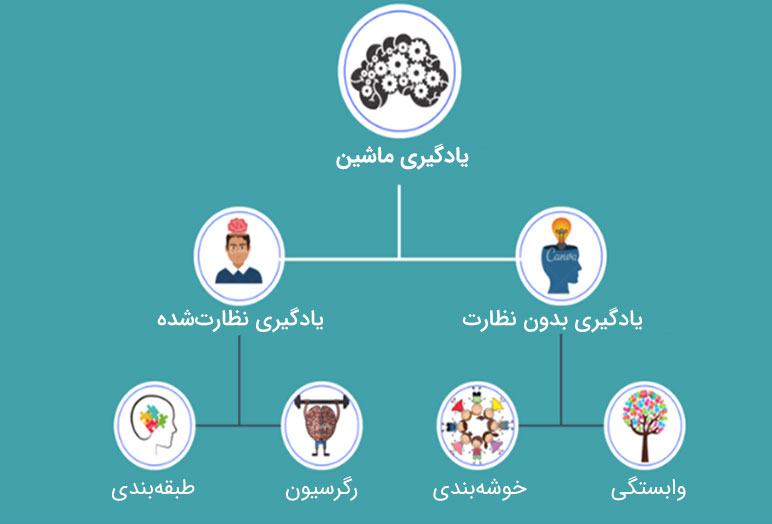
تفاوت اصلی بین یادگیری با نظارت و بدون نظارت: دادههای برچسبدار
یکی از تفاوتهای بسیار مهم بین یادگیری نظارت نشده (unsupervised learning) و یادگیری با ناظر در نوع دادههایی است که آنها استفاده میکنند. در یادگیری با ناظر از دادههای ورودی و خروجی برچسبدار استفاده میشود؛ در حالی که الگوریتم یادگیری بدون نظارت اینگونه نیست. در یادگیری بی نظارت، مدل یادگیری بدون نظارت نیروی انسانی و به طور مستقل کار میکند تا ساختار ذاتی دادههای بدون برچسب را کشف کند.
| یادگیری تحت نظارت | یادگیری بدون نظارت |
| دادههای ورودی دارای برچسب هستند | دادههای ورودی بدون برچسب هستند |
| از مجموعه دادههای آموزشی استفاده میکند | فقط از مجموعه دادههای ورودی استفاده میکند |
| برای پیشبینی استفاده میشود | برای تحلیل استفاده میشود |
| طبقهبندی و رگرسیون | خوشهبندی، برآورد چگالی و کاهش ابعاد |
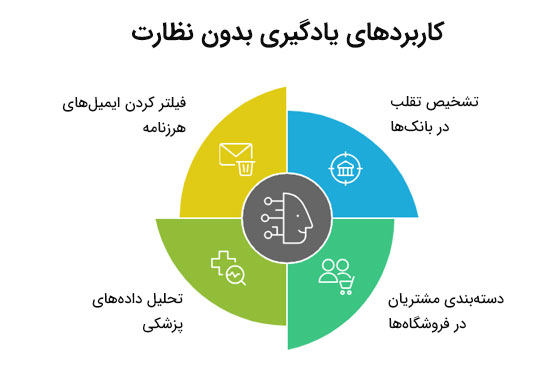
کاربردهای یادگیری بدون نظارت
تشخیص تقلب در بانکها
به لطف یادگیری بی نظارت، بانکها میتوانند در کسری از ثانیه تشخیص دهند که کدام یک از تراکنشها مشکوک و تقلبی هستند. فرایند تشخیص به این صورت است که الگوریتم یادگیری بدون نظارت میتواند تراکنشهایی که رفتار عجیبی دارند را شناسایی کند؛ بدون اینکه کسی از قبل به سیستم بگوید که این تراکنشها مشکلدار هستند.
در واقع این سیستمها با مطالعه تراکنشهای گذشته که مشخص شده کدامیک تقلبی بودهاند، یاد میگیرند الگوهای مشکوک را تشخیص دهند. به این ترتیب میتوانند در لحظه جلوی تراکنشهای مشکوک را بگیرند و از ضرر مالی جلوگیری کنند.
دستهبندی مشتریان در فروشگاهها
یکی از کاربردهای الگوریتم یادگیری بدون نظارت در فروشگاههای آنلاین است. مثلا تصور کنید یک فروشگاه آنلاین مثل دیجیکالا بخواهد متوجه شود که مشتریانش اغلب چند دسته هستند؟ فرضا او مشتریان خود را به سه دسته تقسیم میکند؛ یک عده که همیشه گوشی موبایل، لپ تاپ و وسایل الکترونیکی میخرند، یک عده که بیشتر مواد غذایی میخرند، یک عده هم فقط لباس و کفش تهیه میکنند. با یادگیری بی نظارت میتوان این دستهها را به طور خودکار تشخیص داد و به هر گروه پیشنهادهای مخصوص خودشان را ارائه کرد.
تحلیل دادههای پزشکی
یادگیری ماشین بدون نظارت میتواند به پزشکان کمک کند الگوهای مخفی در دادههای بیماران را پیدا کنند. مثلا ممکن است ماشینها با بررسی پروندههای پزشکی، تصاویر پزشکی و اطلاعات ژنتیکی بیماران، بتوانند الگوهای رایج را کشف کنند و متوجه شوند یک نوع از بیماری در جمعیتی خاص با ویژگیهای مشترک، رایج است.
فیلتر کردن ایمیلهای هرزنامه
الگوریتم یادگیری بدون نظارت با مطالعه نمونههای زیادی از ایمیلهای مفید و هرزنامهها، یاد میگیرد که چطور ایمیلهای جدید را دستهبندی کند و چطور ایمیلهای هرز و ناخواسته را تشخیص دهد. به این ترتیب کاربران از شر پیامهای مزاحم یا خطرناک در امان میمانند.
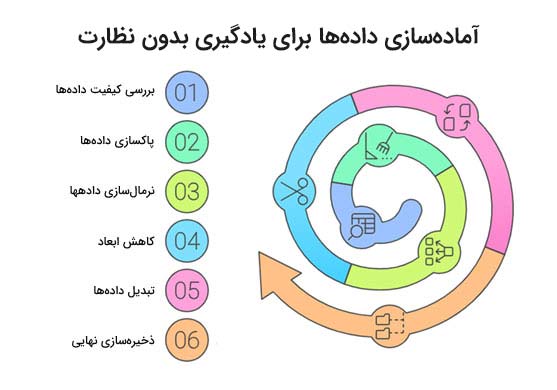
آمادهسازی دادهها برای یادگیری بدون نظارت
هر چند که یادگیری بدون نظارت یک روش هوشمندانه برای کشف الگوهای و ساختارهای پنهان در دادههای بدون برچسب است؛ اما موفقیت این روش تا حد بسیار زیادی به کیفیت و نحوه آمادهسازی دادهها وابسته است؛ زیرا که بدون آمادهسازی مناسب، حتی قویترین الگوریتمها نیز نمیتوانند نتایج قابل اعتمادی تولید کنند.
برای اینکه یک سیستم یادگیری بدون نظارت بتواند به درستی الگوهای پنهان در دادهها را کشف کند؛ باید این دادهها را با دقت انتخاب کرد. در ادامه مراحل کلیدی دادهها را بیان میکنیم.
بررسی کیفیت دادهها
اولین مرحله در انتخاب دادههای مناسب برای یادگیری بی نظارت، این است که مطمئن شویم دادههای ما دقیق و قابل اعتماد هستند؛ مثلا میتوان قیمت محصولات را برای اطمینان از منطقی بودن آن چک کرد یا تاریخها را برای اطمینان از درست ثبت شدن آنها بررسی کرد. در این مرحله، اعتبارسنجی دادهها نیز اهمیت دارد تا مطمئن شویم دادهها دقیق و قابل اعتماد هستند و مدل نتایج قابل اتکایی تولید میکند.
پاکسازی دادهها
در این مرحله باید دادههای نامناسب را پیدا و سپس اصلاح کرد و همچنین باید دادههای گمشده، مقادیر پرت، دادههای تکراری و نویزهای احتمالی را نیز شناسایی کرد.
نرمالسازی دادهها
در این مرحله باید همه دادهها را در یک محدوده استاندارد قرار دهیم. مثلا وقتی دادههای مختلفی داریم مانند سن (۰-۱۰۰) و هم درآمد (میلیونها تومان)، باید همه را در یک مقیاس مشابه بیاوریم.
کاهش ابعاد
در فرایند آمادهسازی دادهها برای یادگیری ماشین بدون نظارت، اگر دادههای زیادی داریم، با روشهای هوشمندانهای تعداد آنها را کم میکنیم تا پردازش آن راحتتر صورت بگیرد.
تبدیل دادهها
در این مرحله دادههای غیرعددی به شکل دادههای عددی تبدیل میشوند؛ مثلا رنگهای (قرمز، آبی) و… را به عدد تبدیل کنیم.
ذخیرهسازی نهایی
در آخر، دادههای آماده شده را طوری ذخیره میکنیم که برای الگوریتمهای یادگیری ماشین قابل استفاده باشند. همچنین اعتبارسنجی دادهها و الگوریتمها، تضمین میکند که نتایج یادگیری بدون نظارت معتبر و کاربردی باشند.
انواع روشهای یادگیری بدون نظارت
دو نوع روش یادگیری بدون نظارت وجود دارد؛ یکی خوشهبندی و دیگری وابستگی. روش خوشهبندی (Clustering) مثل این میماند که شما یک سبد میوه داشته باشید و بخواهید آنها را دستهبندی کنید. کامپیوتر بدون اینکه اسم میوهها را بداند صرفا از روی رنگ، شکل یا اندازه میوهها آنها را گروهبندی میکند. در ادامه روش خوشهبندی را به شکل مبسوطتر توضیح میدهیم.
در روش وابستگی (Association) کامپیوتر الگوهای تکرارشونده و ارتباط بین موارد مختلف را پیدا میکند. مثلا مدلهای یادگیری متوجه میشوند که کسانی که لپتاپ میخرند اغلب موس هم میخرند. این روشها به کامپیوتر کمک میکنند تا در دادههای بزرگ، الگوها و روابط پنهان را پیدا کنند؛ بدون اینکه نیاز به راهنمایی مستقیم انسان داشته باشد.
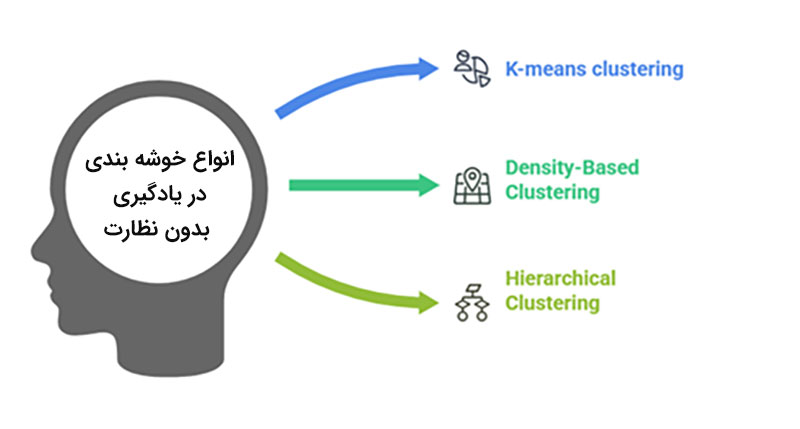
انواع خوشهبندی در یادگیری بدون نظارت
خوشه بندی یک تکنیک یادگیری ماشین بدون نظارت است. در این تکنیک اشیاء یا دادههای مختلف به گروههایی جداگانه تقسیم میشوند؛ در این گروهها اعضای هر گروه بیشترین شباهت را به یکدیگر و کمترین شباهت را با اعضای گروههای دیگر دارند.
روشهای مختلفی برای خوشه بندی وجود دارد که در ادامه به مهمترین این روشها میپردازیم. الگوریتم K-Means Clustering دادهها را به تعداد مشخصی از دستهها تقسیم میکند. مثلا میتوانیم بگوییم که دادههای موجود را به سه دسته تقسیم کند؛ فرض کنید یک سایت فروشگاهی دارید و میخواهید 3 نوع مشتری را شناسایی کند، سه دسته ارزانپسند، معمولی و لوکس پسند را میتوانید با این روش دستهبندی کنید.
بیشتر بخوانید: تشخیص حالت و آناتومی بدن
یکی دیگر از روشهای خوشهبندی DBSCAN (Density-Based Clustering) است که در آن گروههایی که به هم نزدیکتر هستند به طور خودکار خوشهبندی میشوند. مثلا با این روش شما میتوانید مناطق پررفت و آمد در یک شهر را با استفاده از موقعیتیابی مکانی و یا همان GPS شناسایی کنید.
در روش خوشهبندی سلسله مراتبی یا همان Hierarchical Clustering نیز دادهها به شکل یک درخت تقسیمبندی میشوند. به عنوان مثال برای ساخت شجرهنامه حیوانات و دستهبندی آنها از از این نوع الگوریتم یادگیری نظارت نشده استفاده میکنند.
جمعبندی و نتیجهگیری
یادگیری بدون نظارت یکی از قویترین تکنیکهای یادگیری ماشین و هوش مصنوعی است که به کامپیوترها کمک میکند خودشان الگوها را پیدا کنند. این روشها، کاربردهای مختلفی در زندگی روزمره میتواند داشته باشد؛ از سیستمهای پیشنهاددهنده موسیقی گرفته تا تشخیص تقلب در تراکنشهای بانکی و دستهبندی مشتریان در فروشگاههای آنلاین.
همانطور که گفتیم موفقیت در یادگیری بدون نظارت به شدت به کیفیت دادهها و نحوه آمادهسازی آنها وابسته است. مراحلی مانند پاکسازی دادهها، نرمالسازی و کاهش ابعاد، نقش حیاتی در عملکرد بهینه این سیستمها دارند. در نهایت، یادگیری بدون نظارت را میتوان پنجرهای به آینده هوش مصنوعی دانست که با کشف خودکار الگوها و روابط پنهان در دادهها، راه را برای توسعه سیستمهای هوشمندتر و کارآمدتر هموار میکند.








