
در دنیای امروزی، یکی از فناوریهایی که با سرعتی باورنکردنی به پیشرفت خود ادامه میدهد، AI یا همان «هوش مصنوعی» است. هر شخص که به نوعی با ابزارهای مبتنی بر AI سروکار دارد، اولین سوالی که از خود میپرسد این است؛ چگونه این ابزارها تا این اندازه هوشمند عمل میکنند؟ برای پاسخ به این سوال، میبایست به پشت پرده هوش مصنوعی نگاهی بیندازیم و با مفهوم شگفتانگیز مدل زبانی بزرگ (LLM) آشنا شویم.
این مدلها، معمار بسیاری از سرویسها و ابزارهایی هستند که به صورت روزانه با آنها تعامل داریم: از چتباتهای هوشمند گرفته تا دستیارهای صوتی و مترجمهای مبتنی بر AI. اما آیا واقعاً میدانیم این مدلها چگونه کار میکنند؟ چگونه از کلاندادهها یاد میگیرند و مفاهیم را پردازش میکنند؟ در این مقاله، به سفری جذاب به دنیای مدلهای زبانی میرویم و با مفهوم، کاربرد و انواع LLMها، به طور کامل آشنا میشویم.
مدل زبانی بزرگ (LLM) چیست؟
تعریف مدلهای بزرگ زبانی را با یک سؤال شروع میکنیم؛ آیا میتوان ساختمان مستحکمی را پیدا کرد که بر زیربنایی اصولی بنا نشده باشد؟ هر سازهای که مبتنی بر روند ساخت مهندسی بنا شده باشد، نیازمند پایهریزی قابل اطمینانی است که ایمنی ساختمان را تضمین کند و هرچه این سازه بزرگتر و بلندتر باشد، مساحت و کیفیت زیربنا نیز افزایش پیدا میکند.
بیشتر بخوانید: پردازش گفتار چیست؟
سرویسهای مبتنی بر هوش مصنوعی هم بیشباهت به این سازهها نیستند و برای عملکرد صحیح به زیرساختی قدرتمند نیاز دارند. این دقیقاً همان نقطهای است که LLMها پتانسیل واقعی خود را به نمایش میگذارند و با ارائه زیرساختهای مورد نیاز، توسعه بسیاری از ابزارهای مبتنی بر AI مانند چتباتهای هوشمند، دستیارهای صوتی و… را امکانپذیر میکنند. به طور خلاصه، برای پاسخ به پرسش مدل زبانی بزرگ (LLM) چیست، میتوان تعریف زیر را ارائه کرد:
«LLM یا مدل زبان بزرگ، نوعی مدل هوش مصنوعی است که با استفاده از کلاندادههای متنی و معماریهای پیشرفته مانند ترنسفورمرها (Transformer) بهمنظور درک، پردازش و تولید زبان طبیعی طراحی شده است.»
مدلهای زبانی، مسیر توسعه پیچیده و دشواری را طی میکنند که در ادامه به آن میپردازیم.
LLM مخفف چیست؟
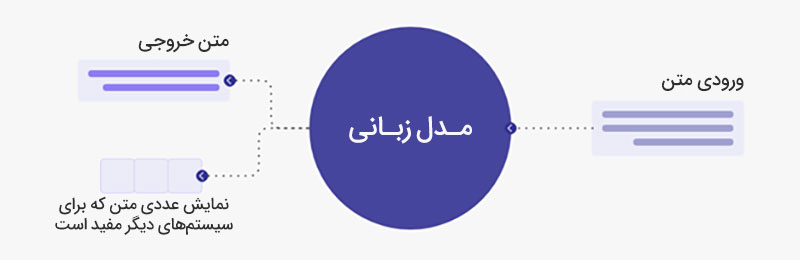
در جریان آشنایی با مدلهای بزرگ زبانی، یکی از پرتکرارترین کلماتی که با آن مواجه میشویم، عبارت LLM است؛ اما LLM مخفف چیست؟ این عبارت مخفف «Large Language Model» است که به چند مفهوم مختلف اشاره دارد. اولین واژه «Large» یا همان «بزرگ» است که به حجم عظیم دادههایی که مدل بر پایه آن آموزش میبیند و همچنین تعداد بسیار زیاد پارامترهای آن اشاره دارد.
عبارت “Language Model” یا «مدل زبانی» نیز به توانایی این مدلها در پردازش و شبیهسازی زبان انسانی مربوط میشود. این عبارت در زمینههای علمی، تحقیقاتی و صنعتی برای اشاره به مدلهای بزرگ زبانی مورد استفاده قرار میگیرد.
مراحل توسعه مدلهای بزرگ زبانی
مراحل توسعه مدل زبان بزرگ (LLM)، یکی از پیچیدهترین فرایندها در حوزه هوش مصنوعی است که نیازمند ترکیبی از دادههای حجیم، معماریهای پیشرفته و منابع محاسباتی قدرتمند است. برای ساخت یک LLM کاربردی، طبق مراحل زیر پیش میرویم:
1. جمعآوری و پیشپردازش دادهها
در گام نخست، میبایست دادههای متنی حجیم و متنوعی جمعآوری شود. این دادههای از منابع گوناگونی مانند کتابها، مقالات علمی، صفحات وب، شبکههای اجتماعی، نظرات کاربران و… به دست میآید. پس از جمعآوری، دادهها به مرحله پیشپردازش سپرده میشوند تا دادههای نویزی، غیرمرتبط، تکراری و نامناسب از آنها حذف شود.
علاوه بر این، در مرحله پیشپردازش، اطمینان حاصل میشود که تمامی کاراکترها استانداردسازی شوند و مواردی مانند حروف کوچک و بزرگ، فاصله و نیمفاصله، نحوه صحیح نگارش املایی و… به دقت مورد بررسی قرار میگیرد.
2. طراحی معماری مدل
تا پیش از این، برای توسعه مدلهای زبانی از معماریهای زیر استفاده میشد:
- شبکههای GRU (Gated Recurrent Unit)
- شبکههای حافظه بلند-کوتاه (LSTM – Long Short-Term Memory)
- شبکههای بازگشتی (RNNs – Recurrent Neural Networks)
- Bag-of-Words
- n-grams
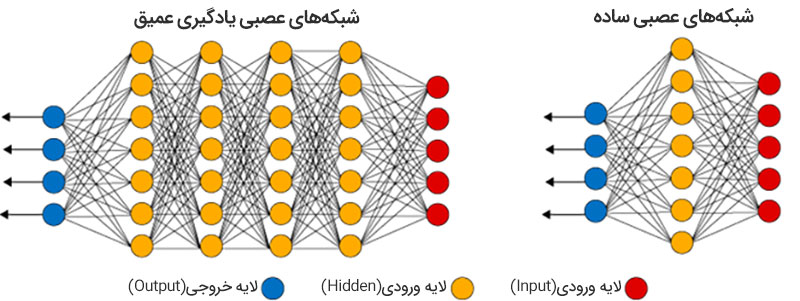
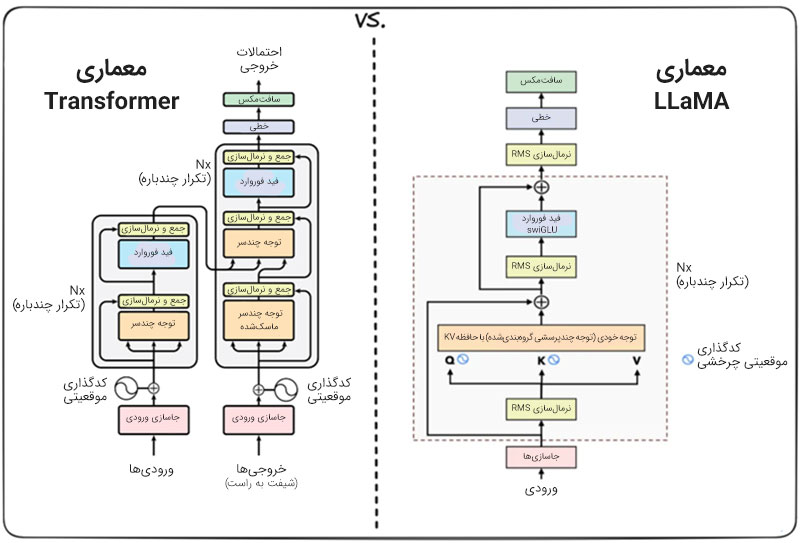
اما پس از روی کار آمدن فناوری تحولآفرین ترنسفورمرها، این معماری جایگاه خود را در دل مدلهای زبانی بزرگ تثبیت کرد. این معماری از مفاهیمی همچون مکانیزم توجه (Attention Mechanism) و شبکههای عصبی عمیق (Deep Neural Networks) استفاده میکند تا پیچیدگی و روابط عمیق بین کلمات را درک کند. مدلهای مشهوری همچون GPT، BERT و Llama از معماری ترنسفورمرها استفاده میکنند و ضریب نفوذ این معماری در LLMهای مختلف همچنان رو به افزایش است.
3. آموزش مدل
در این مرحله، همه چیز برای توسعه یک مدل زبانی مهیاست و میتوان فرایند آموزش را آغاز کرد. آموزش LLM شامل دو بخش اصلی است:
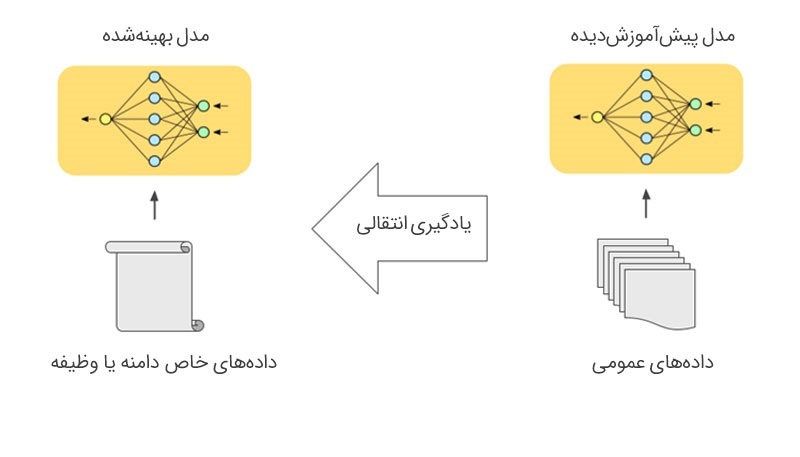
پیشآموزش (Pre-training): مدل با استفاده از کلاندادههای عمومی که پیش از این جمعآوری شده، الگوهای زبانی و وابستگیهای متنی را میآموزد و تلاش میکند تا همانند انسانها، مفهوم یک متن را درک کند. پیشآموزش را میتوان به مقطع ابتدایی تشبیه کرد که اصول خواندن و نوشتن را به طور عمومی به دانشآموزان یاد میدهد.
تنظیم دقیق (Fine-tune): در مرحله تنظیم دقیق، مدل برای انجام وظایفی خاص آموزش میبیند تا در زمینههایی مانند خلاصهسازی، ترجمه، پاسخگویی به سؤالات و… عملکردی چشمگیر از خود به نمایش بگذارد. این مرحله نیز بیشباهت به مقطع کارشناسی و دانشگاه برای انسانها نیست؛ مقطعی که در آن میآموزیم که در یک حوزه مشخص متخصص شویم و پا را از دانش عمومی فراتر بگذاریم.
4. ارزیابی و بهینهسازی
مدلهای زبانی بزرگ به طور مداوم مورد ارزیابی و بهینهسازی قرار میگیرند تا از عملکرد دقیق و قابل اطمینان آنها اطمینان حاصل شود. این ارزیابی شامل مراحل زیر است:
- معیارهای ارزیابی: برای ارزیابی مدل از معیارهای مختلفی مانند دقت (Accuracy)، معیار F1، BLEU برای ترجمه و ROUGE برای خلاصهسازی متون استفاده میشود. این معیارها، توانایی و کیفیت مدل را در انجام وظایف خاص مورد ارزیابی قرار میدهد.
- تحلیل خطا: پس از ارزیابی، نتایج عملکرد مدل بررسی شده و خطاهای آن شناسایی میشوند. این خطاها ممکن است ناشی از دادههای ناکافی، معماری مدل یا روشهای آموزش باشند.
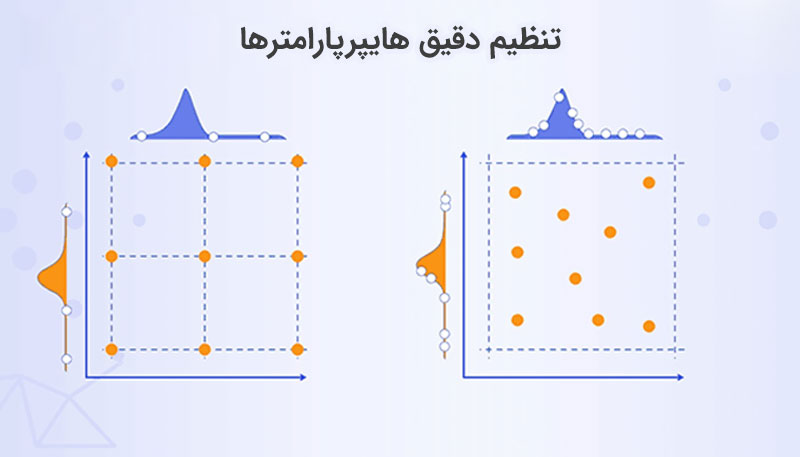
- بهینهسازی مدل: برای بهبود عملکرد مدل، از تکنیکهایی مانند تنظیم نرخ یادگیری (Learning Rate)، تغییر معماری مدل و استفاده از تکنیکهای پیشرفتهای مانند تنظیم دقیق هایپرپارامترها (Hyperparameter Tuning) استفاده میشود. بهعلاوه، تزریق دادههای جدید یا پاکسازی شده به مدل میتوانند در بهبود عملکرد LLM تأثیر بسزایی داشته باشد.
- تحلیل خطا: پس از ارزیابی، نتایج عملکرد مدل بررسی شده و خطاهای آن شناسایی میشوند. این خطاها ممکن است ناشی از دادههای ناکافی، معماری مدل یا روشهای آموزش باشند.
- شبیهسازی شرایط واقعی: مدل در سناریوهای واقعی مورد آزمایش قرار میگیرد تا کارایی آن در شرایط عملی ارزیابی شود. این مرحله تضمین میکند که عملکرد مدل نه تنها در شرایط تئوری، بلکه در کاربردهای عملی نیز قابل اعتماد است.
5. استقرار و بازخورد
پس از آموزش و ارزیابی، مدل در سیستمهای مختلف مورد استفاده قرار میگیرد. این فرایند شامل مراحل زیر است:
- استقرار: مدل زبانی به صورت API، نرمافزار و یا دیگر ابزارهای کاربردی در دسترس کاربران قرار میگیرد. یکی از نیازمندیهای حیاتی این مرحله، فراهمکردن زیرساختهای مناسب برای پاسخگویی به درخواست کاربران است.
- جمعآوری بازخورد کاربران: عملکرد مدل در دنیای واقعی توسط کاربران ارزیابی میشود و بازخوردهای آنان در مورد دقت، سرعت و کارایی مدل جمعآوری میشود.
- اصلاح و بهروزرسانی: با توجه به بازخورد کاربران، مدل بهصورت منظم بهروزرسانی میشود. این بهبود شامل مواردی مانند رفع مشکلات گزارششده، افزودن دادههای جدید و افزایش تعداد پارامترهای مدل است. تداوم بهروزرسانی، مهمترین فاکتور در این مرحله است؛ چرا که سازگاری همیشگی مدل با نیازهای متغیر کاربران را تضمین میکند.
مدلهای زبانی بزرگ برای توسعه و طیکردن این پنج مرحله به سختافزارهای پیشرفته و پرهزینهای نیاز دارند که اغلب تنها در اختیار غولهای تکنولوژی است. این مجموعههای بزرگ، علاوه بر سختافزارهای گرانقیمت، به کلاندادههای عظیمی دسترسی دارند که کار توسعه LLMهای اختصاصی را برای آنها به امری سادهتر تبدیل میکند؛ اما این بدان معنا نیست که شرکتهای کوچک و کاربران شخصی قادر به توسعه مدلهای زبانی نیستند. اگر قصد توسعه یک مدل زبانی را دارید، اطمینان پیدا کنید که LLMای که توسعه میدهید با توان سختافزاری شما هماهنگ است.
کاربردهای مدل زبانی بزرگ (LLM) چیست؟
همانطور که پیش از این اشاره کردیم، مدلهای زبانی نقش زیربنایی برای بسیاری از ابزارهای مبتنی بر هوش مصنوعی را ایفا میکنند و امروزه در سرویسهای هوشمند متعددی مورد استفاده قرار میگیرند. LLMها به دلیل تواناییهای بینظیر زبانی خود، در حوزههای مختلفی مورد استفاده قرار میگیرند و کاربردهای آنها تنها منحصر به یک یا چند ابزار خاص نیست. در ادامه، برخی از مهمترین کاربردهای مدل بزرگ زبانی (LLM) را بررسی میکنیم.

دستیارهای هوشمند و چتباتها
یکی از رایجترین کاربردهای LLMها را میتوان در دستیارهای مجازی و چتباتهای هوشمند مشاهده کرد؛ چتباتهای مانند ChatGPT و Gemini و دستیارهایی مانند Siri و Google Assistant که امروزه به عضوی جداییناپذیر از زندگی ما تبدیل شدهاند، از مدلهای زبانی بزرگ قدرت میگیرند و میتوانند نحوه پاسخگویی انسانی را شبیهسازی کنند.
تولید محتوا و ویرایش متن
مدل زبانی بزرگ نقش مؤثری در تولید محتوای متنی و ویرایش متون ایفا میکند؛ بهطوری که در حال حاضر به صورت گستردهای برای ایجاد مقالات، پستهای بلاگی، ایمیلها و حتی نوشتن کتاب مورد استفاده قرار میگیرد.
بیشتر بخوانید: بهترین اپلیکیشن و سایتهای تبدیل متن به صدا
LLMها متناسب با نیاز کاربر، متون باکیفیت و حرفهای خلق میکنند که گاهی اوقات تشخیص تفاوت آن با محتوای نگارش شده توسط انسان به سادگی قابل تشخیص نیست. علاوه بر این، مدل زبانی بزرگ میتواند حجم زیادی از دادهها را در کوتاهترین زمان ممکن ویرایش و خطاهای نگارشی را برطرف کند.
ترجمه زبان
ابزارهای ترجمه مانند Google Translate سالیان سال است که مشغول به فعالیت هستند به روشهای مختلفی، متنهای دریافتی را به زبانهای دیگر ترجمه میکنند؛ اما پس از ظهور مدلهای زانی بزرگ، عملکرد ابزارهای ترجمه دستخوش تحول جدی شد. حال مترجمهای هوشمند، تنها به ترجمه عین به عین کلمات بسنده نمیکنند و با درک مفهوم هر عبارت و جمله، ترجمهای روان از متن دریافتی را در اختیار مخاطب قرار میدهند. این روش باعث میشود تا مفهوم هر کلمه در جمله معنا پیدا کند و کلماتی با املای یکسان و معنای متفاوت، به اشتباه ترجمه نشوند.
تحلیل کلاندادهها
یکی از مفیدترین قابلیتهای مدل زبانی، توانایی تحلیل کلاندادههای عظیم است. LLMها میتوانند حجم زیادی از دادهها را در مدتزمان کوتاهی تجزیهوتحلیل کند و اطلاعات کلیدی را از کوهی از اسناد حجیم استخراج کند. این قابلیت تحلیل پیشرفته باعث میشود تا در کنار صرفهجویی در زمان و هزینه، بتوانیم به پیشبینی روندها بپردازیم و تصمیمهای بهتری اتخاذ کنیم.
کاربردهای مدلهای زبانی تنها به موارد فوق ختم نمیشود و در عرصههایی مانند تدریس و آموزش زبان، پاسخ به سؤالات، توضیح مفاهیم پیچیده به زبان ساده، خلق آثار هنری، تولید شعر، متون ادبی و… کاربرد بسیاری دارد.
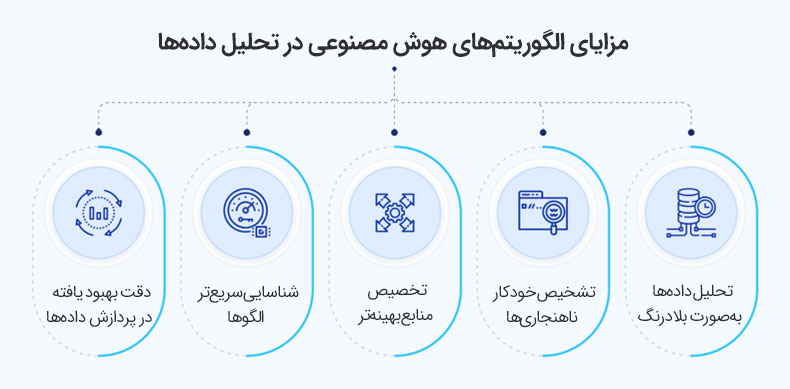
فناوریهای مورد استفاده در مدلهای زبانی بزرگ
برای آشنایی بیشتر با مدلهای زبانی (LLM)، میبایست نحوه ساخت LLMها و فناوریهای بهکار رفته در آنها را با دقت مورد بررسی قرار دهیم. مدلهای زبانی بزرگ، مجموعهای از پیشرفتهترین تکنولوژیهای حوزه AI را در دل خود جای داده و به نوعی، پرچمدار عرصه هوش مصنوعی به حساب میآید؛ پس جای تعجب ندارد که در ادامه با بررسی فناوریهای بهکار رفته در LLMها، با نام برخی از جدیدترین تکنولوژیهای روز دنیا مواجه شوید.
1. پردازش زبان طبیعی (Natural Language Processing – NLP)
پردازش زبان طبیعی یا NLP، مجموعهای از تکنیکها و روشهایی است که به ماشینها این امکان را میدهد تا زبان انسانی را درک کنند و با آن به تعامل بپردازند. این فناوری بخش جداییناپذیری از مدلهای زبانی بزرگ است و طیف وسیعی از وظایف مانند تحلیل معنایی، تشخیص موجودیتهای نامدار، ترجمه زبان و تولید متن را شامل میشود. مدلهای NLP به کمک یادگیری ماشین و الگوریتمهای پیشرفته میتوانند جملات و متنهای پیچیده را تجزیهوتحلیل کنند و با آنها به طور معناداری تعامل داشته باشند.
2. یادگیری عمیق (Deep Learning)
یادگیری عمیق را میتوان یکی از شاخههای مهم یادگیری ماشین برشمرد. این فناوری برای شبیهسازی فرایندهای یادگیری انسان طراحی شده است و برای دستیابی به این هدف، عملکرد مغز انسان در پردازش دادهها را با استفاده از شبکههای عصبی پیچیده شبیهسازی میکند. مدلهای زبانی بزرگ برای یادگیری ویژگیهای زبان و ایجاد روابط معنایی پیچیده از شبکههای عصبی عمیق استفاده میکنند و با تکیه بر پتانسیل این فناوری، ویژگیهای زبانی را با دقت بالایی شبیهسازی کرده و پاسخهای بسیار دقیقی ارائه میدهند.
3. شبکه عصبی ترنسفورمر (Transformer Neural Networks)
ظهور «شبکه عصبی ترنسفورمر» بهعنوان نقطه عطفی در پیدایش LLMهای پیشرفته امروزی شناخته میشود. این معماری که توسط Vaswani و همکاران او در سال 2017 معرفی شد، انقلابی در زمینه پردازش زبان طبیعی ایجاد کرد و باعث شد تا زیرساختهای مورد نیاز برای توسعه چتباتهای هوشمندی مانند ChatGPT فراهم شود.
برخلاف مدلهای قدیمیتر که برای پردازش دادهها بهطور خطی و ترتیبی عمل میکردند، شبکه ترنسفورمر قادر است اطلاعات را بهصورت موازی پردازش کند و این باعث شده تا سرعت و کارایی مدلها به طور چشمگیری افزایش پیدا کند.
ترنسفورمرها برای مدلهای زبان مانند GPT و BERT گزینهای ایدهآل به حساب میآید؛ چرا که روابط پیچیده میان کلمات در یک جمله را شبیهسازی کرده و با استفاده از مکانیسم توجه (Attention Mechanism) برای بخشهای مهم متن وزن و اهمیت بیشتری قائل میشود.
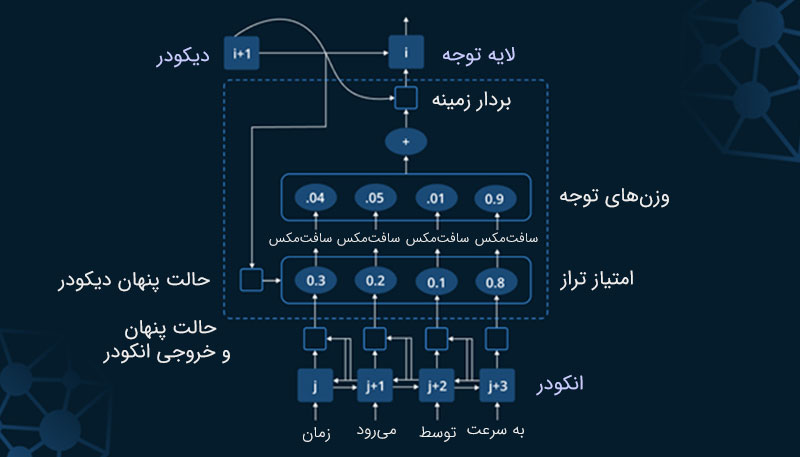
4. مدلهای ترنسفورمر بزرگ (Large Transformer Models)
مدلهای ترنسفورمر بزرگ (مانند GPT-3) با استفاده از تعداد زیادی پارامتر و کلاندادههای عظیم ساخته میشوند و به همین واسطه، قادرند حجم زیادی از اطلاعات را در مدت زمان کوتاهی پردازش کنند.
مدلهای ترنسفورمر بزرگ، تواناییهای قابلتوجهی در تولید متن طبیعی، پاسخ به سؤالات، خلاصهسازی مطالب، و بسیاری از وظایف دیگر دارند و با استفاده از معماری ترنسفورمر و یادگیری عمیق، قادرند فرایند پیچیده پردازش زبان طبیعی را با دقت و سرعت بالایی تکمیل کنند.
5. یادگیری خودنظارتی (Self-supervised Learning)
یکی دیگر از فناوریهای کلیدی که به موفقیت مدلهای زبانی بزرگ کمک شایانی کرده است، «یادگیری خودنظارتی» است. در این نوع یادگیری، مدل بدون نیاز به دادههای برچسبگذاری شده، اطلاعات را از دادههای خام میآموزد.
این روش به مدلها اجازه میدهد تا در مقیاسهای بزرگ، دادهها را تجزیهوتحلیل کنند و ویژگیهای مفید آنها را برای انجام وظایف مختلف بیاموزد. یادگیری خودنظارتی در فرایند پیشآموزش مدلهایی مانند BERT و GPT مورد استفاده قرار میگیرد و یکی از ارکان اصلی توسعه مدل زبانی بزرگ (LLM) به حساب میآید.
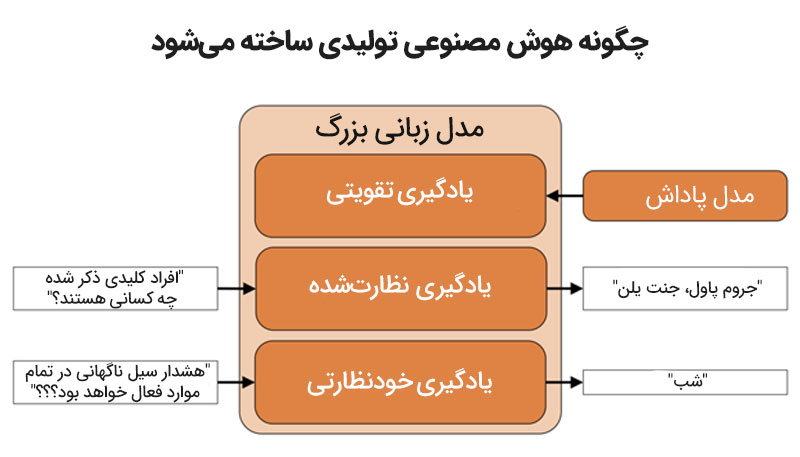
6. پردازش موازی و محاسبات توزیعشده
با توجه به حجم بالای دادهها و پیچیدگیهای مدلهای زبانی بزرگ (LLM)، استفاده از پردازش موازی و محاسبات توزیعشده برای آموزش این مدلها ضروری است. مدلهای ترنسفورمر بزرگ نیاز به منابع محاسباتی زیادی دارند که معمولاً از طریق خوشههای محاسباتی توزیعشده و پردازندههای گرافیکی (GPUs) تأمین میشود. این تکنولوژیها کمک میکنند تا فرایند آموزش مدلها سریعتر و کارآمدتر شود و زیرساختهای پردازشی موجود، به بهینهترین شکل ممکن استفاده شود.
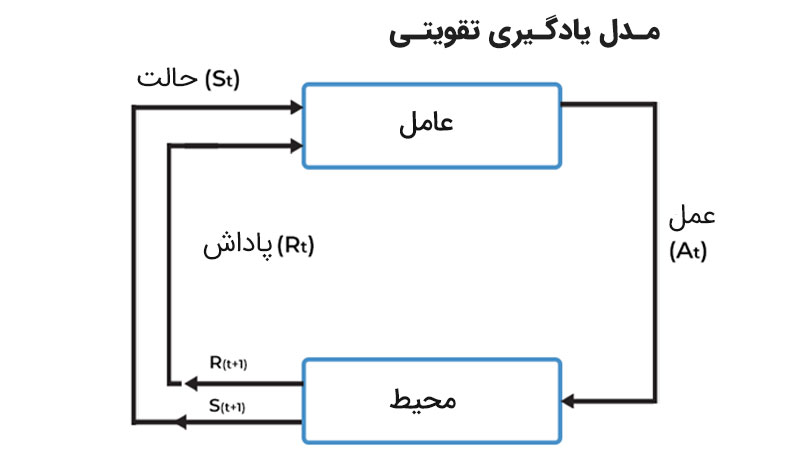
7. مدلهای تقویتشده (Reinforcement Learning)
«مدلهای تقویتشده» بهویژه در زمینه بهینهسازی عملکرد مدلهای زبانی و ارتقا دقت آنها مورد استفاده قرار میگیرد. در این رویکرد، مدلها از طریق تعامل با محیط و دریافت پاداشهای مربوطه، به تدریج به بهترین عملکرد خود دست پیدا میکنند. این تکنیک بهویژه در توسعه مدلهایی که قادر به پاسخدهی سؤالات پیچیده و انجام وظایف چندگانه هستند، مورد استفاده قرار میگیرد.
فناوری مدلهای زبانی بزرگ (LLM)، روزبهروز در حال پیشرفت است و انتظار میرود در آینده، الگوریتمها و تکنولوژیهای جدید دیگری هم به جمع فناوریهای اشارهشده اضافه شوند.
معرفی بهترین مدلهای زبانی بزرگ (LLM) در دنیا
امروزه LLMهای بسیاری به صورت متنباز (Open Source) و Closed Source در دسترس کاربران و توسعهدهندگان قرار دارد که هرکدام مزایا و معایب مختص به خود را دارند. در این بخش، تعدادی از بهترین مدلهای زبانی بزرگ دنیا را بررسی میکنیم و به موشکافی ویژگیهای هر یک از این مدلهای میپردازیم.
در نهایت، به برخی از برترین LLMهای فارسی نگاهی میاندازیم و مناسبترین گزینهها برای توسعهدهندگان داخلی را معرفی میکنیم.
مدل GPT (Generative Pre-trained Transformer)
اگر «مدل GPT» را پیشتاز عرصه مدل زبانی بزرگ (LLM) بدانیم، بیراه نگفتهایم. این مدل بر پایه معماری ترنسفورمر توسعه یافته است و یکی از پیشرفتهترین و تأثیرگذارترین LLMهای دنیای هوش مصنوعی محسوب میشود.
در حال حاضر، مدل GPT بهصورت دوجهته و موازی فعالیت میکند و مکانیزم توجه (Attention Mechanism) را برای درک رابطه میان کلمات در جملهها به کار میگیرد؛ این در حالی است که در نسخه اولیه GPT، این مدل به صورت یکطرفه (Unidirectional) طراحی شده بود و فقط میتوانست بر اساس تحلیل کلمات قبلی، خروجیهای بعدی را تولید کند.
این رویکرد، در عین داشتن محدودیتهای بسیار، باعث شد تا سرعت و کارایی مدل در انجام وظایفی مانند تولید متن بهبود پیدا کند. در نسخههای پیشرفتهتر GPT مانند GPT-3 و GPT-4، مقیاسپذیری به طور فزایندهای افزایش پیدا کرده و حال میتوانند متون پیچیده و موضوعات گسترده را به سادگی درک کنند.
ویژگیها:
- توسعه یافته بر اساس معماری Transformer
- قابلیت درک متنهای پیچیده و تولید محتوای خلاقانه
- آموزش دیده بر روی مجموعه دادههای عظیم و متنوع
کاربردها:
- تولید محتوا (مقالات، داستانها و پستهای وبلاگ)
- پاسخگویی به سؤالات کاربران در قالب چتباتها
- ترجمه و خلاصهسازی متون
نقاط قوت:
- عملکرد عالی در موضوعات عمومی و تخصصی
- تولید متون شبهانسانی با خطای حداقلی
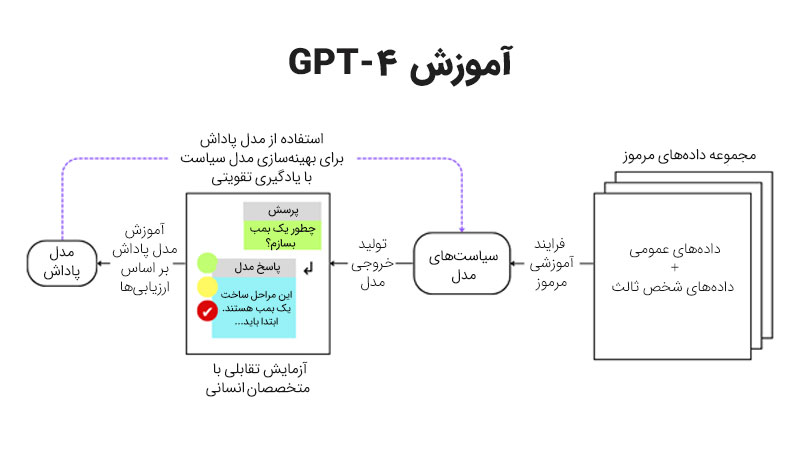
مدل BERT (Bidirectional Encoder Representations from Transformers)
مدل BERT، یکی از نخستین مدلهای زبانی است که توسط Google Research معرفی شد و یکی از پیشگامان است که تکنیک یادگیری دوجهته (Bidirectional Learning) را پایهریزی کرد. برخلاف مدلهای یکجهته مانند نسخههای اولیه GPT، BERT توانست با استفاده از معماری ترنسفورمر، متنهای دریافتی را به طور کامل از هر دو جهت (چپ به راست و راست به چپ) تحلیل و بررسی کند.
این ویژگی باعث شد تا BERT معنای کلمات را نه فقط بر اساس کلمات قبلی یا بعدی، بلکه بر پایه زمینه کامل جمله درک کند. بهعنوانمثال، در جملهای مانند “او در حال نوشیدن شیر است”، BERT میتواند با استفاده از کلمات اطراف تشخیص دهد که منظور از کلمه “شیر”، شیر نوشیدنی است نه شیری که به عنوان حیوان شناخته میشود.
یکی از نکات کلیدی در طراحی BERT استفاده از روش ماسک کردن کلمات (Masked Language Modeling) است. در این روش، برخی از کلمات در جمله ورودی به صورت تصادفی با یک ماسک جایگزین میشوند و مدل تلاش میکند این کلمات را بر اساس زمینه پیشبینی کند.
این تکنیک به BERT کمک میکند تا درک عمیقتری از روابط معنایی و نحوی در متن پیدا کند و محتوا را شبیه به یک انسان بفهمد. مدل BERT برای انجام وظایفی خاص مانند دستهبندی متن، پاسخگویی به سؤالات و تشخیص موجودیتهای نامدار (Named Entity Recognition) مورد استفاده قرار میگیرد و توانسته تاکنون به عنوان یکی از کاربردیترین LLMهای حاضر در اکوسیستم هوش مصنوعی شناخته شود.
ویژگیها:
- استفاده از یادگیری دوجهته برای تجزیهوتحلیل متن
- توانایی درک روابط پیچیده بین کلمات
کاربردها:
- بهینهسازی موتورهای جستجو (SEO) و فهم عبارات جستجو شده
- تحلیل احساسات در متن
- پاسخگویی به سؤالات خاص و تخصصی
نقاط قوت:
- عملکرد قوی در وظایف دستهبندی متن و استخراج اطلاعات
- انعطافپذیری بالا برای سفارشیسازی
مدل PaLM (Pathways Language Model)
مدل PaLM، یکی دیگر مدلهای زبانی مشهور دنیاست که توسط Google توسعه پیدا کرده است. این مدل با استفاده از معماری Pathways طراحی شده و به عنوان یک سیستم آموزشی چندوظیفهای و با قابلیت مقیاسپذیری بسیار بالا شناخته میشود. PaLM با هدف رفع محدودیتهای مدلهای پیشن ایجاد شد و توانست با استفاده از تکنیک تقسیم بار پردازشی به چندین مسیر موازی (Pathways) و بهرهگیری از یادگیری توزیعشده، چندین وظیفه مختلف را به صورت همزمان انجام دهد؛ این در حالی است که مدلهای سنتی، قادر نبودند که چند وظیفه را به صورت همزمان انجام دهند و برای هر وظیفه، میبایست مدل جداگانهای طراحی میشد.
یکی از ویژگیهای برجسته PaLM، استفاده از Fine-tune مبتنی بر انتقال دانش (Transfer Learning) است. این مدل ابتدا بر روی مجموعه دادههای عظیم و متنوع آموزش میبیند و سپس برای وظایف خاصتر تنظیم میشود. PaLM همچنین برای کاهش مصرف منابع محاسبی در عین حفظ کیفیت پاسخگویی، از روش یادگیری پراکنده (Sparse Learning) برای فعالسازی بخشهایی استفاده میکند که هنگام انجام وظیفه مورد نیاز است. از آنجایی که این مدل توانایی قابلتوجهی در درک عمیق زبان انسانی دارد، در انجام کارهایی مانند ترجمه، تولید متون پیچیده، پاسخگویی به سوالات چندلایه و… کاربرد خود را به نمایش میگذارد.
ویژگیها:
- مقیاسپذیری بسیار بالا با استفاده از Pathways
- توانایی انجام چندین وظیفه با یک مدل واحد
کاربردها:
- کمک به توسعه نرمافزارهای هوشمند
- درک معنایی عمیقتر در وظایف زبانی
نقاط قوت:
- دقت بینظیر در تولید متون پیچیده.
- قابلیت انطباق با وظایف خاص
مدل LLaMA (Large Language Model Meta AI)
همانطور که انتظار میرفت، Meta (شرکت مادر فیسبوک) هم در زمینه مدلهای زبانی منفعل نبود و با توسعه مدل زبانی بزرگ LLaMA، یکی از برترین LLMهایی که تا به امروز در دسترس توسعهدهندگان قرار گرفته است را به بازار عرضه کرد. یکی از ویژگیهای مهم و جذاب LLaMA، «متنباز» بودن این مدل است که به عموم افراد و توسعهدهندگان اجازه میدهد تا به مدلی پیشرفته و حرفهای دسترسی داشته باشند و آن را بر حسب نیاز خود شخصیسازی کنند.
این مدل با هدف کاهش وابستگی به سختافزارهای سنگین و بهینهسازی پردازش زبان طبیعی (NLP) طراحی شده است و برخلاف اکثر مدلهای زبانی که برای فعالیت به منابع پردازشی عظیمی وابسته هستند، LLaMA میتواند با استفاده از منابع محدود هم عملکرد درخشانی از خود به نمایش بگذارد. LLaMA برای دستیابی به این هدف، از معماری فشردهسازی و بهرهگیری از تکنیکهای بهینهسازی حافظه پیشرفته استفاده میکند و به همین جهت، این امکان را برای محققان، پژوهشگران و توسعهدهندگان فراهم میکند که LLaMA را بر روی سیستمهای شخصی خود به اجرا درآورند. مدل زبانی محبوب متا، پس از عرضه با استقبال گستردهای از جانب کاربران و فعالان حوزه هوش مصنوعی رو به رو شد و تاکنون برای انجام وظایف گوناگونی مانند چتباتها، تولید محتوای متنی، ترجمه، خلاصهسازی محتوا و… مورد استفاده قرار گرفته است.
ویژگیها:
- سبکتر و کممصرفتر از مدلهای مشابه
- ارائه نتایج سریع و با کیفیت بالا
کاربردها:
- تعامل در شبکههای اجتماعی هوشمند
- توسعه چتباتها و ابزارهای خدمات مشتری
نقاط قوت:
- کارایی بالا در سختافزارهای معمولی
- دسترسی آسان برای پژوهشگران و توسعهدهندگان
معرفی بهترین مدلهای زبانی بزرگ (LLM) فارسی
زیستبوم هوش مصنوعی فارسی هم از قافله مدلهای زبانی بزرگ (LLM) عقب نمانده و طی سالهای گذشته، شاهد عرضه LLMهای پرقدرت و کاربردی بسیاری بودیم. این مدلها با تمرکز بر زبان فارسی، به توسعهدهندگان و برنامهنویسان کمک میکنند که سرویسها و ابزارهایی مبتنی بر نیاز مخاطب فارسیزبان تولید کنند و چالشهای استفاده از مدلهای خارجی را از میان بردارند. در ادامه، تعدادی از برترین مدلهای زبانی فارسی را بررسی میکنیم:
گروه مدل زبانی «درنا»
«درنا»، یکی از محبوبترین گروه مدل زبانیهای فارسی است که از زمان عرضه تاکنون، مورد استقبال بسیاری از توسعهدهندگان قرار گرفته است. درنا شامل مدلهای 3، 7، 8 و 13 میلیارد پارامتری است که مدل 8 میلیارد پارامتری این گروه به صورت متنباز عرضه شده است. تمامی مدلهای موجود در گروه مدل زبانی درنا با تمرکز بر زبان فارسی توسعه پیدا کردهاند و توانستهاند در فهم و تولید محتوای فارسی، عملکردی به مراتب بهتر نسبت به مدلهای خارجی از خود به نمایش بگذارد.
چندی پیش، عضو 8 میلیارد پارامتری این گروه به نسخه دوم بهروزرسانی شد و تیم توسعهدهنده از طریق این آپدیت، قابلیتهای جدیدی را در دسترس توسعهدهندگان قرار داد. یکی از قابلیتهای جذاب نسخه دوم، ارتقا پنجره ورودی توکنها از 8 هزار به 128 هزار توکن است. این ارتقا، به مدل امکان دریافت ورودی طولاتیتر را میدهد و محدودیتهای دریافت و تولید متن را تا حد زیادی از بین میبرد. همچنین قابلیت اتصال به APIها و سرویسهای شخص ثالث به نسخه دوم مدل 8 میلیاردی درنا اضافه شده تا این مدل به یکی از کاملترین LLM های فارسی تبدیل شود.
گروه مدل زبانی توکا
مرکز تحقیقات هوش مصنوعی پارت موفق شد در گروه مدل زبانی «توکا»، برای نخستینبار مدل زبانی مشهور و کاربردی BERT Large را بر پایه دادههای فارسی آموزش دهد و آن را به صورت متنباز به دست توسعهدهندگان برساند. این مدل با ظرفیت 500 گیگابایت معادل 90 میلیارد توکن، توسعه داده شده و توانسته علیرغم حجم پایین خود، عملکردی قابل قبول از خود ارائه دهد. از همین رو، پژوهشگران، توسعهدهندگان، برنامهنویسان و استارتاپهای حوزه هوش مصنوعی میتوانند این مدل را بر روی سختافزارهای نهچندان بالارده اجرا کنند و بدون نیاز به زیرساختهای گرانقیمت، از پتانسیلهای نامحدود LLMها استفاده کنند.
گروه مدل زبانی شاهین
گروه مدل زبانی «شاهین» شامل دو مدل 8 و 32 میلیارد پارامتری است که بر اساس جدیدترین معماری روز دنیا توسعه یافتهاند. نسخه 8 میلیارد پارامتری شاهین، هماکنون به صورت متنباز در دسترس قرار دارد و توسعهدهندگان میتوانند استفاده رایگان از آن را آغاز کنند. مدلهای شاهین از API و سرویسهای شخص ثالث پشتیبانی میکنند و این امکان را دارند که دادهها را از منابع گوناگون دریافت کنند. علاوه بر این، مدلهای شاهین با پنجره ورودی 128 هزار توکنی خود، عملکردی قابل توجه در پردازش متون بلند دارند و دست کاربران را برای ارسال و دریافت متون بلند باز میگذارند.
نتیجهگیری
مدلهای زبانی بزرگ به لطف پیشرفتهای چشمگیر در فناوریهای پردازش زبان طبیعی، یادگیری عمیق، شبکه عصبی ترنسفورمر و دیگر تکنیکهای نوین، توانستهاند به ابزارهای قدرتمندی در بسیاری از صنایع تبدیل شوند.
این مدلها نهتنها درک زبان طبیعی را به سطح جدیدی رساندهاند؛ بلکه امکان ایجاد سیستمهای هوشمندتر و پاسخدهی سریعتر به نیازهای کاربران را فراهم کردهاند. انتظار میرود که با ادامه پیشرفت این فناوریها، شاهد تغییرات و پیشرفتهای بیشتری در نحوه تعامل انسان با ماشین باشیم و روزبهروز به مفهوم هوش مصنوعی عمومی (AGI) نزدیکتر شویم.








